Now that some dust has settled on the once visionary ideas of early hypertext systems and the Web has developed in ways then unforeseen in the past 32 years, it might be of value to do a little check-in on some key points and collate if they have found their way into our global network of today. Are there challenges opening up or have we found new approaches already? In the following chapter, I tried to consider and carve out emphases that I’ve noticed researching the pre-web systems and take voices of the hypertext community into consideration.
Interactivity & Collaboration
Thinking about FRESS and Intermedia, which were mostly thought out as collaborative tools where users weren’t just readers but writers and editors who could set their own links. Even in Xanadu, selected editors would compile new knowledge together. This functionality, although conceptualised in the early CERN days, didn’t make the cut into today’s Web.
The first ever web browser was also an editor, making the web an interactive medium, the problem was that it only ran on the NeXTStep operating system. With recent phenomena like blogs and wikis, the web is beginning to develop the kind of collaborative nature that its inventor envisaged from the start.

Through social media and collaborative endeavours like Wikipedia, today’s Web(2.0) seems more interactive than ever before. Still, it’s important to note, that those platforms are always built on top of the Webs’ internal structure, which doesn’t allow editing or annotations on a structural level. They are interactive despite it, not because of it. HTML can be very limiting and people are trying to work around those limits.
Much of the Web’s interactivity seems to consist of discussions or commentary, emotional reactions e.g. ‘likes’ and personal messaging or content creation. In my eyes, it seems much more fragmented and ego-representative data compared to the idealised goal of collaboratively working together on something bigger, like building knowledge. One could compare this effect to the oral age translating into the digital space, a network of fragmented social information spanning between our devices.
Still, just in recent years, the rise of collaborative real-time online tools has started to take off more and more. A few examples are Etherpad for collaborative writing, Miro for mind mapping or Figma for designing and the Google Docs editors, in which I’m writing this thesis right now. They are examples of how the Web’s interactivity can be used in commercial and educational contexts.
Generating, editing and working together online has never been easier and more intuitive and Wikis are a great instance of voluntary many-to-many collaboration. They come in my opinion, closest to a community trying to edit knowledge networks together, like at Brown and at least represent the idea of colliding what we already know into Hypertext, as Ted Nelson dreamed of. Still, somehow they don’t quite hold up to the grand vision of global scholastic communities tightly conjoining on their fields or the universal approach of the Xanadu idea with everyone working together in one universal tool with proper citing and royalty systems established.
“It’s also frustrating that using hypertext has become more passive,” Andy says, “and that’s because of commercialization. When you’re on a commercial web page, there’s a rigid separation between creating and consuming
Learn More
Navigation, Hierarchies & Indexing
In early March this year, I made a shocking discovery. Many of the collections I had made within my Flickr account suddenly were almost empty, what a loss! A visit to the forum soothed me, that I wasn’t alone but soon brought bad news: the contents of The Internet Archive Book Images account had been deleted from the platform without warning.
This is devastating, had to be my favourite thing on the internet, no hyperbole.Please tell me the metadata was backed up before the account was deleted? In theory the images are still somewhere in the internet archive (not in a browsable form).. but all the time people spent exploring the 5 million plus images and favouriting them + adding them to galleries, just gone?Even just the view counts for each image would allow the most popular images to be found again..
What this upset user pointed out, was very true. The metadata generated within the huge dataset maybe was just as valuable as the continents themselves and with it an interface that supported the categorising.
With great masses of data and information, it gets harder and harder to navigate and work out the knowledge it might entail. Tagging and sorting are two exemplary bottom-up indexing strategies that have thrived in a flat hierarchy Web.
Now I’m sure Ted Nelson would like to differ, as he thinks that HTML is a terribly hierarchical markup-template-hamburger. And he might be right, but in the grand scheme of things and at a structural level, the Web is a network of documents equal to each other and connected by links, just as in “As we may think”.
Bush, by contrast, envisioned a flat system with no classification scheme. Indeed, the Web’s openness and lack of hierarchy—for better and worse—has strong conceptual roots in Bush’s bottom-up document structure.
There is no ingrained central Index or table of content to the Web like we know it from libraries, printed encyclopaedias or the Mundaneum. So besides hyperlinks, how do we actually navigate the Web if not top-down? By algorithm-driven search engines like Google, which have basically replaced typing URLs.
A great advantage of digital text is being able to perform a full-text search, but the computing power needed just wasn’t there with early hypertext systems. I found that Intermedia must have already implemented a similar algorithm but seems to be the only system researched that advertised search as a feature. It seems like the trailblazers didn’t quite grasp the full power search could unleash.
Google’s PageRank revolutionised search because they understood that frequency isn’t the only aspect of a good result, quality is too!
Nonetheless, navigation was a big issue that was discussed by researchers at the time. There are two main functionalities I could observe.
One was graphical maps of the network, similar to tree diagrams or mind maps. They were a very popular approach and could be found within FRESS, Intermedia and Hypercard. From what I’ve seen they were also used for following hypermedia systems. I’m actually quite surprised they haven’t really caught on and found their way into the Web. It might have been due to the immense growth that would have hit illustrative limitations quite quickly, but it’s not hard to imagine them with some kind of zoom capabilities or at least as a navigational element on singular websites instead of hierarchical header menus.
The second is observed in the semantics of FRESS, through the separation of structure and formatting, contrary to HTML. This gave opportunity for different depictions of the contained contents, combined with the aforementioned keyword tags and filter options.
The user can view just the top n levels of the structure — a map whose level of detail is defined by the user. This facilitates rapid movement between sections and makes editing and global navigation easier.
FRESS provided a variety of coordinated views and conditional structure and view-specification mechanisms. The user had final control over how and how much of the document was being displayed — unlike with embedded markup like HTML.
From how I understand it, this kind of functionality, although desirable, would be hard to implement on the web due to its manyfold content types and structures. Still, some individual websites are making an effort of offering adapted options for navigational structures to their content. Most welcome from my perspective.
Learn More
Linking & Trails
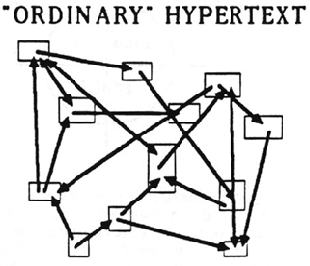
The Web’s lack of bidirectional links, as mentioned before, was alienating to most Hypertext researchers at the time. In a bi-directionally linked network, both parties know about being linked and both documents can refer to each other, which can enrich one and the other. To my knowledge FRESS, Intermedia and Microcosm were using links that went in both directions. At Intermedia, they were stored in an additional database. They also used ‘fat links’ which are multidirectional, so one anchor could hold links to multiple targets.
the technology to handle a worldwide database of bidirectional links was untenable at the time. But it made the web incredibly fragile – if someone renames a document, all the links pointing to that document break and produce the dreaded ‘404 error’ when followed
And while linkbases and constructive hypertext were easily maintained in relatively contained research and classroom environments, or on small networks of computers all running the same operating system, they would have quickly become unmanageable on a global scale.
Experts suggest it would’ve been impossible for the Web to implement and upkeep an external database during its exponential growth. Still, Tim Berners-Lee must have considered the option, as one can trace in his notes. In the end ‘back links’ turned out to be an important factor for Google’s PageRank algorithm to estimate the importance of a page.
To build a system that wouldn’t be able to prevent link rot seemed irresponsible at last to the early hypertext crowd as well. Link rot describes links that lead to nowhere, causing an error as the reference document has been lost, deleted or changed location. On the Web, it leads to ‘Error 404’. Most of the previous systems either prevented that by automatically updating links when documents were moved or deactivated the connection automatically once the target document was deleted. The Web tries to counteract this problem through permalinks or crawlers that search for dead links, quite ineffectively. A recent Harvard study took the New York Times as an example and found that a quarter of its deep links have already been rotten. (Clark, 2021) A big problem for traceability on the Web.

Another factor to consider when evaluating links is granularity or as Van Dam puts it ‘creaminess’. It defines how detailed links work, with the finest granularity being one single letter. Intermedia provided a very fine grain, so when following a link it would lead you to the desired paragraph, word or graphic. You can see it in action here, note how the desired target note is highlighted through a blinking dotted frame. FRESS had similar functionality.
On the Web, high granularity is mainly possible within the same document. As soon as one links to a node outside, it is most likely a generic URL to a whole document. There are exceptions, like target websites that provide a higher granularity, for example, YouTube which allows generating links to a specific video start time.
Something that hasn’t been noted above is the collaborative nature of link-making in all of Brown’s systems. With users as editors, they naturally were able to make their own links that would become part of the content and were visible to other users, contrary to the Web, where links are embedded within the document by one author. Intermedia even went a step further and implemented an individual web of links, separate from the document, that was stored in an external database. The closest the Web gets to that is probably bookmarks, but they aren’t really comparable considering the depth of functionality. Del.icio.us used to be a popular platform for social bookmarking and stands as an example of how valued the social aspect of linking can be.
Bush’s idea of linked trails through heaps of information is also found in some of the pre-Web systems. In Intermedia and Microcosm Mimics, specified paths could be defined and shared, this was mostly advertised for educational purposes and re-introduces linearity into the networked system that can help beginners navigate or set up a certain narrative. Hypercard inherently adopted some kind of linearity through the stack metaphor and with that was mostly consisting of thematic paths, which arrows as a main interface element. Maybe today’s browser history somehow represents a trail, but it doesn’t really paint a clear or defined narrative, nor is it meant for sharing.
As Ted Nelson seems obsessed with visual links it is worth a mention here, I think opposed to just visually implying there is an underlying connection, his definition of ‘visual’ implies showing the connected source link right next to where it was implemented, so it’s always put in context. This idea is very close to the two-display concept introduced by Bush but doesn’t seem to have caught on.
Last but not least Alex Wright brings up an interesting idea that resonates a bit with how FRESS was set up and Otlet’s Universal Decimal Classification. In a Google Tech Talk, he explains that links could also carry a meaning, he calls it gradation of links, which could imply the relationship between the two nodes, if they agree or disagree etcetera. We already know of a similar adoption in FRESS, where links could be tagged with keywords. Maybe something similar is thinkable using classes or IDs in HTML.
People can easily fall into the belief that the web is ‘done’, but there are tons of things, like links that don’t break, that existed in Brown’s systems in the past and hopefully will find their way into the web of the future
Learn More
Citing & Embedding
Citing on the Web or generally in word processing environments today is still extremely tedious and faulty. Even with helpful tools, like Zotero, that I’m using for this thesis or citation checkers, mistakes can sneak in, links can break and with each layer of citation, it gets more unclear who said what or it gets distorted through paraphrasing. The clipboard with its copy-paste mechanism might have made the process easier, but technically how we cite hasn’t changed for centuries. Links just sped up the process.
Ted Nelson’s proposal for transclusion in Xanadu to me seems to me like a fresh breath of air. The idea to include a citation by pulling and linking it from its original source instead of copying and ‘swallowing’ it, seems only logical. It keeps the content original, reference chains intact and provides direct access, plus an update to the latest version if requested. Intermedia did implement a similar feature, the pull request as shown here. In the example, a graphic is ‘pulled’ into an existing text document and then displayed within. When edited it is updateable. Of course in Intermedia this was easier to accomplish as it only entails a local network.
I understand that to be able to rely on the technology, a Xanadu-like closed and universal database would have to be implemented somehow. Otherwise, we would deal with similar issues, like broken transclusions. Some people see the blockchain as a solution to that - I’m not too sure about that.
The Web actually provides a similar technology through ‘embedding’, videos and iframes can be included in a website and live data can be pulled from external databases, like the universal time.
Still, to my knowledge, there isn’t a system in place for low-granularity text embedding, which would be gratifying. Iframes can be notoriously unstable which is another indicator to work on a more stable system of trust and source reliability.
Using a typical Web link, you change context and engage with new text as you might by going to a library and following a citation from book to book, pursuing a parallel rather than an “inclusive” relationship.
Archiving the Ephemeral Web
Through extensive content shifts and link rot as explained above we have to admit that today’s Web is ephemeral. Although previous systems have employed technologies to prevent those and solved some issues of version control, they all have a common flaw, when examined for their longevity and resilience in order to accommodate the world’s knowledge. They are embedded within their systems, which couldn’t withstand the pace of technological progress, and weren’t accessible within just a few years. Databases have been translated from diskettes to LaserDiscs to CDs to the Cloud. Although we made a great leap forward by being able to store data as bits, we still haven’t figured out a stable enough system of formats to trust for such a big task of preservation. Maybe digital capability hasn’t surpassed paper qualities just yet, as it is stable and directly accessible.
Ironically microfilm still is the most durable option we have today for ensuring longevity, as it’s less susceptible to environmental factors. So Bush’s Memex, although seeming a bit antiquated, still offers the most reliable alternative to our paper libraries today, taking up only a fraction of the space. No wonder it’s the chosen technology for state archives, hoarding rolls and rolls of film in some underground rock tunnel.
Nevertheless, the Web has stuck around with us for 32 years now and we have to take care not too much knowledge is lost in the meantime. The Internet Archive’s Wayback Machine is doing a great job by archiving as much as possible whilst trying to ensure some kind of directed quality control. Right now it has saved 734 billion web pages (“Internet Archive,” 2022) next to its further functions as a digital library, still, it’s like rowing upstream and only so much can be archived. That all these efforts only rely on a voluntary non-profit is insane to me.
It’s vital to recognize that not everything is culturally important and in many cases, especially online ephemerality is desired, like in Snapchat for example.
Accessibility & Copyright
Now let’s discuss a core question. The question of value concerning electronic documents that can now be reproduced indefinitely and cheaply published to a global audience with ease. How can we ensure rights and royalties are retained for authors and creators and at the same time provide accessibility and re-use to as many people as possible when translated into an online hypertext system?
I know this is a problem that probably won’t be solved just by implementing new technology in some systems. It might require global legislative action, and this thesis can only touch on the issue, but still, I feel it needs to be addressed within this conversation of how we want the Web and future hypertext systems to evolve.

In the Web’s early days, it was all about openly sharing scientific knowledge. To quote Tim Berners-Lee again:
The project started with the philosophy that much academic information should be freely available to anyone.
There was a spirit of community building that didn’t care much about licences and rights. What would later be called ‘online piracy’ thrived, because it was so easy on the Internet.
Today information on the Web is not really free. A big chunk is blocked by paywalls or enwrought with advertisements and somehow financed by data resellers.
The Internet simultaneously holds both the utopian promise of free access to all the world’s knowledge and the dystopian potential for the privatisation of all knowledge for the profit of small number of monopolistic corporations.
In contrast to those commercially motivated monetized systems stand online hacktivists like Aaron Swartz, Institutions like the Internet Archive with its Open Library and shadow libraries, who fight against the blocking of access. They are true believers of the world library and are convinced it should be implemented now, either through piracy on platforms like Library Genesis or Sci-Hub or through a library-like lending system, implemented at Internet Archive, which currently is the cause of a critical lawsuit with big publishers, that will decide if it can make use of the fair use policy.

When it comes to academic publishing it gets even more complicated, because it involves prestigious journals and peer reviews. Basically, government-funded scientists write papers, that are reviewed by other government-funded scientists, that then are published by journals that earn a lot of money, paid by libraries funded by the government for people to access the papers. Sounds pretty fucked to me.
Open Access tries to break this vicious circle by convincing scientists to openly publish their papers, to make them accessible and free to reuse. Something that is only possible because of the Webs structure, but it seems like so far the scientific community is having a hard time letting go of old established ways and adopting new relevance criteria.
In other fields, the creative commons licences are a possibility for creators to make their work open to sharing and re-use.
Once copyright expires, usually 50-100 years after the author’s death, in the US the work will be public domain. Project Gutenberg uses that to publish those for free as ebooks.
It gets complicated when the rights are unclear, as proven by the lawsuit around google books, when they tried to implement the world brain all by themselves. What they got was the self-proclaimed world's most comprehensive index catalogue.
In August 2010, Google put out a blog post announcing that there were 129,864,880 books in the world. The company said they were going to scan them all.
They just started carting truckloads of books from big university libraries to a scanning centre for them to be digitised through optical character recognition.
The idea was that in the future, once all books were digitized, you’d be able to map the citations among them, see which books got cited the most, and use that data to give better search results to library patrons.
Google planned to make the books searchable and display snippets to users, just like the system is implemented now. Still to provide that service all books have to be scanned completely. A developer commented, they could be opened up for the world to read within minutes.
Somewhere at Google there is a database containing 25 million books and nobody is allowed to read them.
The Atlantics trial article is worth a read, as it unfolds the complexities of the copyright question in all its ugliness. In the end, the problem of how to deal with out-of-print publications and ones with unclear rights status wasn’t solved but postponed.
The examples set out above are supposed to draw a picture of either extreme, commercial usage with walls around knowledge, or full access through shadow libraries that ignore the laws and with that the creators and authors, whose work they actually value.
There has to be a compromise. Authors shouldn’t have to give away their work for free, because there is no hope of being compensated fairly on any side. Maybe technology can offer solutions, but there will have to be some legislative decisions.
To draw back to hypertext systems, Xanadu was the only proposed system to address this issue, copyright at an infrastructural level. Ted Nelson was convinced that within his closed environment, micropayments per read and usage, directly to the creator, could offer the solution to this crux.
I must admit he had me intrigued. But as easy things can seem in concept as important they can be in implementation. In his most recent ‘demo’ of Xanadocs he shows how restricted content would be displayed: ‘encrypted’ as Webdings tofu. To me as a designer it just seems like a very clumsy solution, that obstructs the flow of the document too much. But at least he is trying out new solutions, we need more of that momentum.
Stretchtext, one of Ted’s early ideas could also be considered an asset for accessibility in a different realm. He suggested a kind of detailed adjuster for the complexity of text as part of the interface. It’s imaginable in levels for example as kindergarten, plain language, high school, college, and PhD. While there are already examples where another option of text complexity is offered, editing still often is too much of a time/cost factor. In the future, it is quite imaginable to see these options automatically generated through text-based artificial intelligence, like GPT-3.
Although dictionaries for defining specific terms had been thought of in Intermedia, another similar valuable aspect, that had been completely overlooked in previous systems, found its way into the web: automated translation. This allowed a much greater audience to participate. If we want to expand this capability we should ensure all the world will be able to participate in the open web, not just on Facebook satellite service. In some areas, a DVD on a horse is still a faster way to transmit data than the Net, even in Germany.