Systems of Hypertextual Knowledge Transfer on a Way Towards a World Brain. A Trail of Thoughts.
M.F.A. Thesis by Miriam Humm Master of Fine Arts, Klasse Digitale Grafik Hochschule für Bildende Künste Hamburg, Oktober 2022
Cultural Memories
On Knowledge Transfer
A mother octopus caring for her eggs
To reproduce, an octopus mother will find a little underwater den, lay tens of thousands of eggs, carefully guard them and constantly move the water surrounding the little eggs, so fresh oxygenated water will flow between them. She doesn’t leave her place to hunt for months and would starve to death caring for the eggs before they even hatch.
Once the tiny octopus babies are out of their soft egg case, they are left all to their own devices and rely only on the instinct that is embedded in their DNA. There is no adult to teach them how to hunt for food, change colour to assimilate and squirt ink if they are in danger.
I once read that this lack of intergenerational exchange is why their species isn’t already taking over the planet. Their cognitive abilities are beyond impressive and work totally differently from the ones of mammals. Just imagine what an octopus society would look like if they wouldn’t take up most of their life learning everything from scratch, but built upon their parents’ knowledge, easily identify predators and learned about their ancestors.
Humans are different from all other known beings in that they acquire information, store it, process it and transmit it to future generations.
Just like Octomom, humans spend a lot of time and energy on their offspring. Somewhere in evolution we favoured the big brain and paid for it with a long pregnancy period. Luckily homo sapien mothers tend to survive birth and a period of intensive care for our youngest follows. Despite being so intelligent, or to become so, we take quite some time to reach the full capacity of our body and brain. During that period we learn from exploration, but those experiences are backed and extended by the knowledge of the adult generation, which builds upon their predecessors’. This, as Vilém Flusser puts it, “cultural memory” is what I’m interested in, our “unnatural” urge to remember.
Our species transmits acquired and inherited information from generation to generation. This doubly contradicts nature. The Second Principle of Thermodynamics states that information contained within nature tends to be forgotten. Living organisms contradict that principle by preserving and transmitting genetic information. They constitute a memory in defiance of the entropy of nature. Mendel's biological law states that acquired information cannot be transmitted from organism to organism. Our species contradicts that law by having an elaborate cultural memory, progressively storing acquired information to which successive generations have access. This double negation of nature, although only temporary, constitutes the human condition.
Throughout most of human history oral culture was the only way of preserving knowledge for future generations. Stories, songs and poems were the carriers of information and were stored through memory.
For many non-western cultures, oral tradition is still a core technology for transferring traditions and values.
Reading about oral culture made me think about my own upbringing, as I grew up with the palatinian dialect of southwest Germany. I learned to speak in a language (or at least a variation) that isn’t normed or noted down in a dictionary, where words and habituations can change from village to village and tonality is only readable through interpersonal interaction. I even remember learning a song, that I still know by heart, that describes what it means to be a palatinian.
As early humans progressed and started using tools “material culture” was born. Materially stored Information has the advantage of externalising memory. The bits aren’t at risk of simply being forgotten anymore and aren’t subjected to the “errors of noise-disrupted transmission”
Hard objects have the advantage of being relatively stable. A stone knife can preserve information about 'how to cut' for tens of thousands of years. Information stored within hard objects creates informed objects that constitute our 'material culture'.
Stone Axe
Flusser presumes that this material environment is what shaped our propensity to linearity. Translating oral storytelling, which works sequentially as an array of sounds, into objects embedded sequentiality in our culture.
this gesture can be recognized in the stringing of shells to make a necklace
From then on, throughout early human history this ‘common thread’ traverses until we reach a milestone: writing. With such a core technology unlocked, externalised knowledge could now be reconstructed by others independent from time and space, allowing a new level of abstraction and thought that helped humanity progress and keep a record of shared memory.
Prehistoric cave paintings of horses and hands at Pech Merle. (~25,000 BC)
This development began with the lining up of stylized images (of pictograms) and ended with the aligning of phonetic signs (letters) into lines of text.
From then on there was no stopping, humans transferred their thoughts and knowledge to clay, wax, stone, papyrus, parchment, paper and the occasional wall. The start of a human record.
Mesopotamian clay tablet of the earliest writing, 3000 BC. The text records beer given to workers as part of their daily rations.
The Information Age
Now let’s fast forward roughly 5000 years. Paper, bound in books, has established itself as the medium of choice of the written word and Gutenberg invented the moveable-type printing press by 1440, kicking off the printing revolution. This enabled the grand public to extract written knowledge, as opposed to a selected few, which profoundly and permanently altered European society.
Let’s jump a bit further, by 1945 calculations of library expansion stated that every 16 Years our knowledge capacity would double if provided with enough physical space. To our luck, digital storage technology would be developed on time, or we would have drowned in paper at some point.
With the invention of the jacquard loom and its punched cards, humans had figured out a new binary system of storing information, that was clearer and more mathematical than language. A way to talk to machines and with that the start of analogue computing.
This logic, hole or not, yes or no, 1 or 0, is what inspired Claude Shannon, the forefather of information theory. In 1948 he defined it as a Bit, the smallest unit of information we know. With that digital information became quantifiable and programming and compression possible. Designers might recognize the term from Bitmaps, where a pixel is either rendered white or black.
These are exemplary pinpoints on the path towards the Digital Revolution, which marks the beginning of the Information Age. An enormous shift in society, sometimes compared to the Agricultural or Industrial Revolution, that’s still far from concluded. We’re living it right now.
There are many names for the concept of the ‘World Brain’ I’m referring to within this thesis: A World Encyclopaedia, a Mundaneum, a universal library, a Docuverse, a universal knowledge hub, a Total Library, a Universal Bibliography [...]. But they all entail a similar thought, compiling the world’s knowledge in a universal/global system to influence social evolution, be it for scientific progression, education or peace. They vary in scope and implementation, but it’s the idea that counts for me, so at times the term can be used interchangeably depending on context.
The first instance that comes to mind when thinking of a universal knowledge hub is the Library of Alexandria, as one of the most comprehensive and significant institutions of the ancient world, hosting an estimated 400,000 scrolls, which were catalogued in the Pinakes. It is often referred to as a famous example of a devastating loss of knowledge, due to a fire set by Caesar. But it seems like most of the library actually survived the fire and afterwards declined slowly. Either way, it serves as a reminder that we need to look after our collections of knowledge and be weary of centralisation. Now let’s follow that idea and fast forward 2000 years.
La Cité Mondiale
At the beginning of the last century in 1885, Paul Otlet and Henri Lafontaine (who later won the Nobel Peace Prize), two Belgian lawyers, were obsessed with the idea of creating a centre of the world’s knowledge. Globalisation was the hot topic and with a set of megalomaniac ideas stacked onto each other they ultimately planned to build some kind of world city of knowledge, the “Cité Mondiale”, for which Le Corbusier had already made some sketches. (Wright, 2014)
The heart of the project was the ‘Universal Bibliography’ a catalogue of all the world’s published information, recorded with the Universal Decimal Classification system, a top-down taxonomy created by Otlet himself, on 15 million index cards. They offered a fee-based service where people could mail in questions which would be answered by (mostly female) staff with copies of the fitting index cards. An analogue search engine if you will, that answered 1,500 queries a year by 1912. (Wright, 2014)
Mankind is at a turning point in its history. The mass of data acquired is astounding. We need new instruments to simplify it, to condense it, or intelligence will never be able to overcome the difficulties imposed upon it or achieve the progress that it foresees and to which it aspires.
Around the 1930s Otlet extended his visions around the ‘Universal Bibliography’ by planning a world museum, the “Mundaneum” to not just refer to, but house the knowledge, accompanied by a world university and library, all within the city of knowledge. In his plans, this city would be host to leading institutions from all over the world and lead to peace. He was a convinced pacifist and later contributed to the development of the League of Nations and UNESCO.
Tragically none of his grand plans could be realised as Belgium was invaded by Nazi Germany in 1940, the Mundaneum got filled with third Reich art and his life’s work fell into obscurity. Just now he is starting to be recognized as some kind of forefather of information science.
Otlet envisioned the Mundaneum as a tightly controlled environment, with a group of expert “bibliologists” working to catalog every piece of data by applying the exacting rules of the Universal Decimal Classification.
Encyclopaedic Peace
H.G. Wells, Outlet’s and La Fontaine’s contemporary and author of ‘The War of the Worlds’ as well as ‘The Time Machine’, was occupied with similar thoughts. In 1937 he published his essay ‘World Brain: The Idea of a Permanent World Encyclopaedia’. He too advocated for a global index of all bibliographies in the hope of it providing peace and development of human intelligence. The new technology of Microfilm to him was a possible solution to share the contents accordingly. (Wright, 2014)
Young H.G. Wells.
These innovators, who may be dreamers today, but who hope to become very active organizers tomorrow, project a unified, if not a centralized, world organ to "pull the mind of the world together", which will be not so much a rival to the universities, as a supplementary and co-ordinating addition to their educational activities - on a planetary scale. [...] There is no practical obstacle whatever now to the creation of an efficient index to all human knowledge, ideas and achievements, to the creation, that is, of a complete planetary memory for all mankind. And not simply an index; the direct reproduction of the thing itself can be summoned to any properly prepared spot. [...] The whole human memory can be, and probably in a short time will be, made accessible to every individual. [...] Quietly and sanely this new encyclopaedia will, not so much overcome these archaic discords, as deprive them, steadily but imperceptibly, of their present reality. A common ideology based on this Permanent World Encyclopaedia is a possible means, to some it seems the only means, of dissolving human conflict into unity.
To me, it’s astounding how even in a completely analogue, tedious world it was taken for granted that the issue of information glut had to be tackled, come what may. What came, with all force, was a second World War, that set the world brain idea on ice for some years.
Bookwheel, from Agostino Ramelli’s Le diverse et artificiose machine, 1588
If we imagine all the books of the world in one big library, there are still some pitfalls that the classical codex format brings with it. One: Its physicality. Even apart from its high flammability, susceptibility to moisture and acidity, it can be a pain to handle.
Working scholarly means knowing many texts and contrasts of opinions, information that spreads over multiple different volumes. And it takes quite some time and effort to make connections between different sources. So thought Augostino Ramelli, who must have been sick of dealing with the large and heavy printed works of his time. He invented a kind of ‘book ferris wheel’ to sit at and read multiple books in one location with ease, especially “for those who are indisposed and tormented by gout.”
In comparison to the earlier scrolls, the book format, through its browsable pages, made it easier to navigate a text. To extract knowledge from a scroll, it needed to be rolled meticulously section by section - the ultimate linear format. Still, the book as we know it is held together by a thread, holding the pages in a fixed sequence, sorted from the beginning to the end, from introduction to conclusion, from A to Z. Until today this linearity is deeply embedded in our literary tradition.
A fundamental challenge in writing is representing the non-linear world in a linear medium. We’re used to arguments and stories unfolding in a line. Rhetoric and narrative have developed strategies like the syllogism and the flashback for dealing with a multidimensional world in a single path. As successful as these strategies are, they remain constrained to a linear sequence. Traditionally, readers have had little choice but to follow along.
Breaking Linearity
But what if we imagine the document only as a container, holding a collection of chunks of information that can be extracted and used in other contexts? What if we only could pull up the information that is relevant to us at that time? And what if that information could even exist outside of its home document structure and be shared?
In 1945, right after the end of World War II, Vannevar Bush published an article contemplating these questions in The Atlantic called ‘As We May Think’, which would influence many to come and cause ripples which are still relevant today.
Bush wasn’t just anyone, he was a scientist who had become an important figure during the war, as President Roosevelt’s science advisor and by being involved in the Manhattan Project. He before had made relevant contributions to analogue computing with the differential analyzer at MIT and would later contribute to the creation of the National Science Foundation.
He was upset by the inefficiency of scientific progress due to information overload and eager to direct this progress towards better use than destruction, so he introduced a fictional machine that would aid people in navigating Information.
Consider a future device for individual use, which is a sort of mechanized private file and library. It needs a name, and, to coin one at random, "memex" will do. A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.
From "As We May Think", Life, 1945.
Bush suggests Microfilm, which could be pulled up mechanically, as the solution for storing a lot of information within his desk like Memex. He imagined the Encyclopaedia Britannica, reduced to the size of a matchbox.
As he has several projection positions, he can leave one item in position while he calls up another. He can add marginal notes and comments
From "As We May Think", Life, 1945.
A mockup of Fermat’s famous last theorem in the margins of Arithmetica, an example of how important annotations can be.
Convinced that the human brain works differently than static top-down indexes, he proposes making paths or trails that would link pieces of information together to form new ideas, just like thoughts can jump from one point to the other.
associative indexing, the basic idea of which is a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of the memex. The process of tying two items together is the important thing.
It is exactly as though the physical items had been gathered together from widely separated sources and bound together to form a new book. It is more than this, for any item can be joined into numerous trails.
And just like that he had predicted what would later become ‘personal computers’ and delivered the probably first description of what we now call ‘hypertext’.
Presumably man’s spirit should be elevated if he can better review his shady past and analyze more completely and objectively his present problems. He has built a civilization so complex that he needs to mechanize his records more fully if he is to push his experiment to its logical conclusion and not merely become bogged down part way there by overtaxing his limited memory. His excursions may be more enjoyable if he can reacquire the privilege of forgetting the manifold things he does not need to have immediately at hand, with some assurance that he can find them again if they prove important.
The common intellectual heritage shared by each of Otlet, Wells and Bush is their persistent use of the analogy of the human brain in relation to the free and unrestricted flow of information within society, and how their predictions would result in an external information infrastructure which complemented the internal workings of the mind.
Two decades later Ted Nelson, who had been inspired by Bush’s Memex and who thought a lot about these connections, coined the term ‘hypertext’ in his conference paper ‘Complex information processing: a file structure for the complex, the changing and the indeterminate’.
Let me introduce the word "hypertext"***** to mean a body of written or pictorial material interconnected in such a complex way that it could not conveniently be presented or represented on paper. It may contain summaries, or maps of its contents and their interrelations; it may contain annotations, additions and footnotes from scholars who have examined it.[...]***** The sense of "hyper-" used here connotes extension and generality; cf. "hyperspace." The criterion for this prefix is the inability of these objects to be comprised sensibly into linear media, like the text string, or even media of somewhat higher complexity.
Later he specified it a little further, as non-linear text.
Well, by "hypertext" I mean nonsequential writing—text that branches and allows choices to the reader, best read at an interactive screen.
Since this was in 1972, these pictures were of a mockup, not a functioning system. There were no office computers then.
Hypertext surpasses ‘traditional’ text. It can do more than just contain its own information because it provides connections to other nodes. Those links allow readers to jump from an anchor to the reference and follow that path that might as well lead away from the ‘main’ text they started at, or jump them between paragraphs within said starting point. Through that, they can explore the context or relationships between the content.
Since hyper- generally means "above, beyond", hypertext is something that’s gone beyond the limitations of ordinary text. Thus, unlike the text in a book, hypertext permits you, by clicking with a mouse, to immediately access text in one of millions of different electronic sources.
What sets it apart is its networked structure and with that the dissolving of the linearity of text. It is easy to imagine those as divisions within the text but a text itself being built of multiple text chunks.
When interacting with Hypertext readers become active, they select their own path through the provided information just like in “Choose Your Own Adventure” books, but with possibly far more complex outcomes and trails.
A typical Guide window. The mouse button is currently pressed to display a pop-up note.
Nelson even took the idea a step further by incorporating connected audio, video, and other media in addition to text. He named this extension of Hypertext "Hypermedia." In order to keep this thesis within a defined framework, I solely focus on hypertext. While some of the systems discussed are in line with the definition of hypermedia, this concept includes much more that would go beyond the scope.
One of Nelson’s earliest drawings of hypertext and its hypothetical use by a historian. Presented in his paper “Complex Information Processing: A File Structure for the Complex, the Changing, and the Indeterminate”.
literature appears not as a collection of independent works, but as an ongoing system of interconnecting documents.
Ted Nelson argues that most of literary culture has already worked as a hypertext system, through referentiality. Page numbers, indexes, footnotes, annotations and bibliographies are the original analogue paper equivalent to links.
Many people consider [hypertext] to be new and drastic and threatening. However, I would like to take the position that hypertext is fundamentally traditional and in the mainstream of literature. Customary writing chooses one expository sequence from among the possible myriad; hypertext allows many, all available to the reader. In fact, however, we constantly depart from sequence, citing things ahead and behind in the text. Phrases like “as we have already said” and “as we will see” are really implicit pointers to contents elsewhere in the sequence.
Internal links and loops in Vladimir Nabokov’s Pale Fire. A great example of a very cross-referenced novel. Ted Nelson wanted to build a hypertext demo of it at Brown University. Poster by Simon Rowberry.
Traditional print works by “inclusion.” External references are embedded as quotations, becoming integral parts of the referring text.
With this definition a book could be seen as a sequence of citations and commentaries on commentaries, the Talmud is an example of that. It emphasises that literary practice is contextual and referential in its nature as is culture itself.
Edition of the first page of the Babylonian Talmud showing several commentaries next to each other.
These thoughts could be continued with concepts of intertextuality and post-structuralism. Hypertext literature or hypertext fiction are further areas to be investigated, but all surpass the scope of this thesis.
Dreams of the Docuverse
Double cover of ‘Computer Lib/Dream Machines’. It can be read from two directions.
Project Xanadu is the brainchild of Ted Nelson who, when he coined the term hypertext in the 60s only saw it as a part of the bigger system named after the poem "Kubla Khan" by Samuel Taylor Coleridge. Xanadu partly is a yet unrealized utopia, partly an incomplete working prototype, partly living on in other projects. It’s hard to compile a good overview of what Xanadu entails in a compressed form like this, but I will try.
Ted had coined the word hypertext in 1963 to mean “non-sequential writing”, and in 1966, had proposed a system called Xanadu in which he wanted to include features such as linking, conditional branching, windows, indexing, undo, versioning, and comparison of related texts on an interactive graphics screen.
Nelson started thinking about the ways we could deal with text on computers and electronic publishing during his graduate sociology studies at Harvard when he took a computer science course. Radically open to new ideas, but quite understanding of the problems at the time, Ted, a generalist/philosopher rather than a programmer, started to add up his ideal visions of a universal repository hypertext network.
Following Bush’s footsteps he imagined all existing documents in one big network, the “Docuverse”. He was the first to see a connection in how digital computers could facilitate the idea of a “world brain” in the future. How we could store, present and work with information.
Now that we have all these wonderful devices, it should be the goal of society to put them in the service of truth and learning.
In the docuverse there is literally no hierarchy and no hors-texte. The entire paratextual apparatus inhabits a horizontal, shared space.
He was (and still is) convinced that all these connections and relationships between documents could now finally be represented in a digital dataset, just like a digital version of Otlet’s Mundaneum, but not just referring to content but actually hosting the knowledge itself including all of its metadata and previous versions.
The point of Xanadu is to make intertextual messiness maximally functional, and in that way to encourage the proliferation and elaboration of ideas.
Within this net of interwoven connections, all references and quotes could be traced back to their original text and even earlier versions of those in one big network. A new commodity that would advance humanity just like Bush and Wells had imagined.
Now we need to get everybody together again. We want to go back to the roots of our civilization-- the ability, which we once had, for everybody who could read to be able to read everything. We must once again become a community of common access to a shared heritage.
His vision encompassed bidirectional links that went into both directions and were granular about which exact part they reference. He defined different types of hypertext, depending on the level of referentiality.
Basic or chunk style hypertext offers choices, either as footnote-markers (like asterisks) or labels at the end of a chunk. Whatever you point at then comes to the screen. Collateral hypertext means compound annotations or parallel text. Stretchtext changes continuously. This requires very unusual techniques, but exemplifies how "continuous" hypertext might work. An anthological hypertext, however, would consist of materials brought together from all over, like an anthological book. A grand hypertext, then, folks, would be a hypertext consisting of "everything" written about a subject, or vaguely relevant to it, tied together by editors The real dream is for "everything" to tie in the hypertext.
A page in ‘Computer Lib/Dream Machines’ detailing Xanadu.
The underlying technology he called “zippered lists” and presented it at a conference of the Association for Computing Machinery in 1965. For quoting and implementing material from other sources he offered “transclusion”, opposite to copy-pasting, where the source gets lost, transclusion embeds a kind of text patch, a part of the original source within a new document and keeps the connection alive. To me one of the most important elements of his vision.
Nelson proposes transclusion, a system combining aspects of inclusion and linking. A transclusive network implements links so as to combine documents dynamically, allowing them to be read together as mutual citations while they remain technically distinct.
As an author himself, Nelson made sure to address some key issues of sharing documents. Firstly he suggested hosting Xanadu decentralised on local machines, so it couldn’t be under the control of a government or large company. This would also ensure the collection’s longevity to survive natural disasters, through sharing copies on many machines.
it is one relatively small computer program, set up to run in each storage machine of an ever-growing network.
Secondly, he tried to find a setup to fairly handle copyright and royalties for users and authors equally. He found micropayments to be the best solution to that, for each transclusion the author would be reimbursed with a small amount of money, depending on the size of the reference. With publishing on the platform authors would have to grant access to their texts.
We need a way for people to store information not as individual "files" but as a connected literature. It must be possible to create, access and manipulate this literature of richly formatted and connected information cheaply, reliably and securely from anywhere in the world. Documents must remain accessible indefinitely, safe from any kind of loss, damage, modification, censorship or removal except by the owner. It must be impossible to falsify ownership or track individual readers of any document.
Ted Nelson (left) at the Hypertext ’89 conference
With this big idea in his head, an ever-growing list of possible enhancements, it turned out to be an immense challenge for Nelson to implement them technically from his ‘outsider’ humanist standpoint. As persuasive as he could be in his arguments, he did infect some investors and programmers with his idea and convinced them to throw money and energy into the project. To cut the long-winded story short, it never took off.
It’s easy (or maybe just funny) to imagine Xanadu as some kind of nightmarish version of Borges’ Library of Babel, a Windows 95–esque software iteration with every conceivable variation of every text ever, all linked to each other in a dense criss-crossed web of sources and citations.
In 1995 WIRED magazine published an article “The curse of Xanadu”, detailing the developments of Nelson’s Idea. Gary Wolf, the author, called Xanadu “the longest-running vaporware project in the history of computing - a 30-year saga of rabid prototyping and heart-slashing despair” (Wolf, 1995) and Nelson, to outline it nicely as “too far ahead of his time”.
The kinds of programs he was talking about required enormous memory and processing power. Even today, the technology to implement a worldwide Xanadu network does not exist.
A programmer who had worked on Xanadu was quoted as quite disillusioned.
He suspected that human society might not benefit from a perfect technological memory. Thinking is based on selection and weeding out; remembering everything is strangely similar to forgetting everything. "Maybe most things that people do shouldn’t be remembered," Jellinghaus says. "Maybe forgetting is good."
Ted Nelson of course answered the piece with a snappy detailed response. Still, what has been developed and presented to the public under the Xanadu banner to this day are demos and viewers, like Xanadu Space (which - to be fair - features transclusion and a parallel view) but never fully finished products or even a system close to the original vision. To me it seems like Ted had to repeat his credo of the importance of connections so much, he got hung up on the representation of visual links.
XanaduSpace™, Nelson with Robert Adamson Smith (2007)-- Windows only, unchangeable contents.
What I get from it all, is that the project probably could not withstand the powers of ideology vs. technology and the human factor. Still, his full vision is yet to be matched today and he was able to see the great impact hypertextual content would have in a global shared and networked structure.
A universal hypertext network will make “text and graphics, called on demand from anywhere, an elemental commodity. ... There will be hundreds of thousands of file servers—machines storing and dishing out materials. And there will be hundreds of millions of simultaneous users, able to read from billions of stored documents, with trillions of links among them.” Within a few short decades, this network may even bring “a new Golden Age to the human mind.”
“Every talk I give is a Tedtalk. However, that’s been trademarked, so I can’t use it officially.”
Hypertextual Environments
In the years between 1967 and 1990, multiple hypertext systems have been successfully realised and developed within different environments. Educational and scholastic purposes as well as end-user optimised products with user programming and digitisation of archives are examples. A representative selection will be introduced in this section. What sets them apart from the World Wide Web is that they were running on local devices or networks, so the content only got shared and edited within small user groups.
Hypertext systems tend to think of information as nodes (concepts) connected by links (relationships). They will have a way of editing and managing both the nodes and the links. They are usually complete systems which hold all the nodes and links in a robust database.
The young discipline of hypertext was heavily populated with women. Nearly every major team building hypertext systems had women in senior positions, if not at the helm. At Brown University, several women, including Nicole Yankelovich and Karen Catlin, worked on the development of Intermedia.[...]Amy Pearl, from Sun Microsystems, developed Sun’s Link Service, an open hypertext system; Janet Walker at Symbolics singlehandedly created the Symbolics Document Examiner, the first system to incorporate bookmarks, an idea that eventually made its way into modern Web browsers.
Hypertext Editing System (HES) IBM 2250 display console, with lightpen – Chris Braun, Brown University, 1969
The Hypertext Editing System was developed by Andries van Dam and his students at Brown University, with a lot of input from Ted Nelson. It ran on the campus mainframe computer, which at the time was a very valuable resource, worth several million dollars and filling up a whole room. Van Dam’s Team was able to use the machine as a “personal computer” between midnight and 4 AM. (Brown CS: A Half-Century Of Hypertext, n.d.)
It was the first hypertext system ready to use for novices and pioneered the ‘back’ button. Later NASA used it for the documentation of the Apollo space program.
Links were conceptual bridges, shown on screen as asterisks: one at the point of departure, one at the arrival point somewhere else.
oN-Line System, 1968
Bill English preparing for the 1968 Demo.
The oN-Line System or short NLS was developed by Douglas Engelbart at the Stanford Research Center, with the intention to provide a tool to sharpen human intelligence to solve the world’s problems. Its presentation in 1968 would go down in history as “The Mother of all Demos”. Inspired by Bush’s article as a soldier in the cold war, Engelbart dedicated his life to information systems, organising and providing easy access to human knowledge.
In 1968, he used his “Mother of All Demos” to show a conference audience an extraordinary array of revolutionary functionality, including windows, simple line graphics, dynamic linking, text and outline processing, video conferencing, and real-time collaboration.
In an impressive one and a half hours, Engelbart and his team demonstrated through a live video conference how the “intellectual worker” in the future would use the computer. The presentation seems so familiar, because many of the then brand new technologies have been translated into our modern day GUIs. Next to the most remembered invention, the mouse, the system featured windowing, electronic documents with hierarchical hypertext trees and simple drawings.
It featured links, for example, to display the full meaning of an abbreviation, displayed under a dotted line below the ‘main’ content upon clicking the short form. From what I can see in the demo, links weren’t signalised in a special way, and were called ‘hidden links’. Simple line diagrams were used to show structural document setups.
FRESS or the File Retrieval and Editing System was a hypertext system that was built on the previous HES system, also developed by Andries van Dam and students at Brown University. It aimed to incorporate some of Douglas Engelbart’s best ideas from NLS.
FRESS, which first took its name from the Yiddish verb for a gluttonous eater (it used 128 of the mainframe’s 512 kilobytes to run as a time-shared service)
It could use multiple tiled windows, displayed in a WYSIWYG editing environment and implemented one of the first virtual terminal interfaces, that allowed users to log into the system from independent devices. Interactions would be controlled with a Light Pen and corresponding foot pedal.
From the beginning we wanted FRESS users to be both readers and writers, consumers and authors
FRESS word processing already made use of Autosave and pioneered the soon-to-be-essential ‘undo’ feature (Barnet, 2010).
It’s critical because it takes the fear of experimentation away. You can always just undo it.
There were two types of bidirectional links, one used to tag/structure, displayed as “%keyword%”, and the other to jump “%%J” between documents. Links as well as text blocks could be marked with keywords, which in return could operate as a content filter.
A table of contents and an index of keywords would be generated automatically. Additionally, it featured an editable structure space visualisation, that would auto update the edited links.
Links were displayed as ‘markers’ that could be listed next to the text, including a little teaser that would summarise the reference. Opening one of the links would then open the referenced content next to the ‘original’ text.
Some of Ted Nelson’s ideas were incorporated into FRESS, but he distanced himself from the project, as he was disappointed by technological limitations holding back his full vision and van Dam’s pragmatic approach.
Ted was a philosopher, and he wanted to keep hypertext pure.
The team’s focus on word processing (FRESS even was used to format and typeset quite a few books) went strictly against Ted’s belief that hypertext shouldn’t be printed.
An edge-notched card documenting the grant for Van Dam’s educational experiment
We learned that students gain a tremendous amount of insight from having vast amounts of information at their fingertips.
FRESS was used as an educational system at Brown, most notably tested as such in the course “Introduction to Poetry” in 1975 and 1976, which was accompanied by a documentary crew and even tested with a comparison group that didn’t use the system.
compared to a control group that took the course in a traditional setting, the FRESS users attained a deeper understanding of the material and higher satisfaction with the course. On average, students using hypertext wrote three times as much as their computerless counterparts.
Using the valuable campus mainframe computer for the humanities was thought to be improper use by many. Still, Van Dams’ team implemented the course material into the system, the poems in question and additional content that place the poem in context.
Students could use the Light Pen and keyboard to add comments or questions directly to the text and with that form a discussion within FRESS with their classmates and professors.
There was no fancy typeface to give the appearance of professional heft. As a result, students weren’t intimidated by or overly reverent of the professional critics.
“I really believe that we built the world’s first online scholarly community,” van Dam said in an interview. “It foreshadowed wikis, blogs and communal documents of all kinds.”
Scan of a printed screenshot of NoteCards hypertext application Clipped from Conklin, J. (1987) "Hypertext: An Introduction and Survey."
Hypertext-based personal knowledge system, developed by Randall Trigg, Frank Halasz and Thomas Moran and co-designed by Cathy Marshall at Xerox PARC. It was a major influence on Apple’s HyperCard.
NoteCards is an extensible environment designed to help people formulate, structure, compare, and manage ideas. NoteCards provides the user with a “semantic network” of electronic notecards interconnected by typed links.
Each window is an analog of a cue card; window sizes may vary, but contents cannot scroll. Local and global maps are available through browsers. There are over 40 different nodes which support various media.
Links are represented as boxes around the linked text.
organizing and structuring, sketching outlines, and maintaining references. Building connections and viewing them globally helped writers work through their arguments and ideas, and since NoteCards allowed multiple arrangements to exist in parallel, writers could explore various interpretations before settling.
Xerox PARC was an ideal environment to work on hypertext, as it was a very multidisciplinary campus, with anthropologists, linguists, physicists and computer scientists working alongside one another “on a terraced campus built into a wooded hillside overlooking Silicon Valley”. They even offered an Artist-in-Residence Program “which paired artists with technologists to create ambitious new media works.”
Many revolutionary innovations originated there, such as the first personal computer with a mouse driven GUI (Graphical User Interface), the desktop metaphor, laser printing and Ethernet.
As the third major hypertext system originating at Brown University, Intermedia was housed at the Institute for Research in Information and Scholarship or IRIS. It was initiated by Norman Meyrowitz and offered a set of integrated tools and electronic material for students to do scholastic research, on a network of connected computers on campus. In contrast to FRESS, it didn’t just provide a WYSIWYG word processing environment but offered a whole multi-window set of applications.
As its name suggests, Intermedia was plural: it included InterText, a word processor, InterDraw, a drawing tool, Interpix, for looking at scanned images, InterSpect, a three-dimensional object viewer, and InterVal, a timeline editor. Together, these five applications formed an information environment, a flexible housing for whatever corpus of documents a scholar might want to consult.
The integration of many formats, like 3D visualisation tools, marks it as a collaborative hypermedia project. It wasn’t just a staff-fed database but should act as a research platform and base for new ideas through connections points of data.
IRIS designed its hypertext system, Intermedia, from the viewpoint that creating and following links should be an integral part of the desktop user interface metaphor invented by Xerox and popularized by the Macintosh. The cut-and-paste metaphor was a key part of the early Mac experience, and Intermedia put it to good use in its treatment of linking.
All kinds of documents, texts and graphics within the system could be linked together bidirectionally, tagged, filtered and edited again by another user. Links were represented with a link marker as little boxed arrows in superscript and would adapt if one of the anchors moved, to avoid link breakage. To make a link one would select the anchor object, open up a context menu and ‘start link’, then navigate to the desired reference point and ‘complete relation’. If multiple possible links are deposited, a little pop-up window will offer the selection of all possible directions to go.
Linkages weren’t connected with the source material but stored in an external database, leading to an ever-growing ‘personal web’ of connections. Additionally, users could set ‘paths’ as predefined routes through certain documents, close to the idea of Bushes’ trails. With a ‘splice’ selected material could be compiled to be printed together, for example. Full-text search, browsing history and link-map visualisations called ‘plex’ were part of the system as well.
Again the Brown faculty were asked for concepts of educational experiments with the system, which were implemented for a pilot semester in multiple courses, like cell biology and English literature. Those were recorded for a documentary, including student interviews.
Next to the generally very positive feedback some of the critique points by students using the system include performance as the system was quite slow at times or crashed. Other students felt like they cheated, as connections were already provided by other students - working ‘together’ and without the books felt wrong to them.
HyperCard was a hypermedia system running on Apple Macintosh, created by Bill Atkinson. It was one of the first commercially used and widely successful hypertext applications with a big audience.
Reminiscent of Otlet’s index cards and ‘inspired’ by Xerox PARCs NoteCards, this system provided users a very open environment to build their own hypertext card ‘stacks’. Opposite to the index cards they were not just referring to the desired document, but are carriers of the main content themselves. Information was spread on cards that were interconnected through buttons, links and indexes. It linked a database with an editable graphical interface and was a very popular tool within education and in adapted uses like office manuals.
A HyperCard bird
Links were mostly displayed through rounded box buttons as ‘hot spots’ that caused something to happen once clicked. They could link to the next card (as arrows) or stack, cause visual effects or play sounds. There also could be ‘hidden’ buttons, for example within graphics.
The Computer Lab’s Beyond Cyberpunk Hypercard stack
HyperCard content could be shared on floppy disks, so it was possible to buy readymade stacks. It was used as an Address Book, Calendar, To Do list, to play piano notes, as a presentation program (pre PowerPoint) and even for small adventure games, most famously Myst. It came with plenty of templates and graphics ready for use. Images could be scanned as bitmaps and added to HyperCard.
HyperCard as a visual drag-and-drop editor was very easy and intuitive to use. Still, there was the possibility to customise it even further by using HyperTalk, a built-in programming language. It is said to have been an influence on the web as it inspired two key technologies of the Web, HTTP and JavaScript as well as the pointing-finger cursor.
Wendy Hall demonstrating Microcosm in her research lab in the Department of Computer Science at the University of Southampton.
Microcosm was developed by the Department of Electronics and Computer Science at the University of Southampton and is based on the Mountbatten archive.
the library inherited some fifty thousand photographs, speeches recorded on 78 rpm records, and a large collection of film and video. There was no linear sequence to the material, save chronological order, and no hope of fitting it neatly into a database.
It was implemented by a team of researchers around Wendy Hall, who could be seen as one of the female key figures in the hypertext world. Because it holds so many different forms of media it could be categorised as a hypermedia system, rather than just hypertext.
“The archivist came to see me,” Wendy remembers, “and he said, ‘Couldn’t we do something wonderful? I’ve got this multimedia archive, it’s got pictures, it’s got film and it’s got sound. Couldn’t we put it on a computer and link it all together?’ And that was the beginning.
Links are highlighted through bold formatting as ‘buttons’ and multiple links can be offered on click.
‘Micons’ as in ‘moving icons’ can be used as a representation of links for videos. Audio can be linked within the document. The idea of trails or ‘guided tours’ through the content are represented and are called ‘Mimics’.
Microcosm’s core innovation was the way it treated links. Where the Web focuses on connecting documents across a network, Wendy was more interested in the nature of those connections, how discrete ideas linked together, and why—what we would today call “metadata.” Rather than embedding links in documents, as the Web embeds links in its pages, Microcosm kept links separated, in a database meant to be regularly updated and maintained. This “linkbase” communicated with documents without leaving a mark on any underlying document, making a link in Microcosm a kind of flexible information overlay, rather than a structural change to the material.
With this structure Microcosm really put an emphasis on the connections and relations between documents, instead on the document itself.
To start off with, the World Wide Web (short ‘Web’) isn’t the Internet. Although both terms are often used interchangeably, it is important to understand that those are two different technologies that together form most of the online experiences we have today.
Making geographically distant computers talk to each other was a big challenge. It was possible to send data via telephone lines around the 1960s. Then in the United States, the ARPANET was established and around 1977 the Internet was developed out of it. (Web History Primer, n.d.)
The Arpanet in 1971.
The Internet cables that run under the sea are what connect us all together today
The Internet is the actual network we use to send data from device to device through optical cables. Email for example is one service that’s available via the Internet and predates the Web. The World Wide Web is a hypertext system hosted on the Internet, a distributed collection of documents connected through hyperlinks and accessed with a GUI, the browser.
Tim Berners-Lee, pictured at CERN
When Tim Berners-Lee joined Cern in 1980 he wrote a hypertext system called “ENQUIRE” as memory support for himself, making connections was an integral part of it. In its aim, it was quite comparable to the hypertext systems introduced in the previous chapter.
Tim's ENQUIRE effectively allowed users to add nodes to a hypertext system. An interesting property was that you could not add a node unless it was linked to something else.
The project started with the philosophy that much academic information should be freely available to anyone.
But Tim went a step further than his fellow Hypertext researchers. He wanted to make his system accessible to many people working at CERN, globally, through a real worldwide hypertext system on the Internet. So in 1989, he wrote up a proposal to work on such a project on a NeXT machine, the “WorldWideWeb”. It was granted and by Christmas 1990 he had a working prototype running and the server went live. He had solved the key question, of how to make a browsable hypertext network accessible from very different systems and machines. The Web was born.
The one thing missing was a simple but common addressing scheme that worked between files world-wide.
Tim was joined by Robert Cailliau and Nicola Pellow, who worked on a browser to run on any machine. They established HTML as the shared document markup language, employed the URL to identify documents based on the before-established DNS system and used HTTP as the transfer protocol.
Screenshot of the recreated page of the first website
By 1992 the idea took on and there were 50 servers spread over the globe. Marc Andreessen developed the Mosaic browser, which implemented images on websites, rather than opening them in a new window and in early versions pages still could be annotated. Mosaic helped the web take off in the academic sector and by 1993 the web inhabited 2,5% of all Internet traffic (Web History Primer, n.d.). The same year CERN made a crucial decision to put the World Wide Web software under public domain and later released it with an open licence, to “maximise its dissemination” (The Birth of the Web | CERN, n.d.).
In 1994 the World Wide Web Consortium (W3C) was founded by Tim Berners-Lee and by 2001 recognized as the controlling body of the web, with its mission to “lead the Web to its full potential”. Its members consist of commercial, educational, and governmental players and individuals (About W3C, n.d.). Ted Nelson commented in ‘Computers for Cynics 6’ that Tim has a very tough political job at the consortium trying to prevent people to put more and more junk into the Web/browser (TheTedNelson, 2012)
1995 was the year commercial players Netscape and Microsoft published the first version of Internet Explorer, with lots of “balls and whistles”, and the first e-commerce marketplaces were established, which grew the Web exponentially. It flourished. This timeframe, the dot-com boom of the 90s, marks the shift from an academic platform for sharing knowledge to a new kind of web, popularised by companies as we know it today.
In the Web’s HTML standard, any element can be a link, but it must be embedded within the document. A text hyperlink is by default displayed in blue and underlined, it can point to other websites or somewhere within the same website. It consists of the ‘href’ attribute, which points to the link’s destination URL and the link text, which will be displayed to the reader. The target attribute can define if it will be opened in a new window or if it will jump within the current browser window.
Although his paper had been rejected by the Hypertext ’91 conference, Tim Berners-Lee still brought his ten-thousand-dollar NeXT cube, the only computer running the World Wide Web browser at the time, to present it to the ‘hypertext crowd’ in Texas. (Evans, 2018: 164)
Tim Berners-Lee demonstrates the World Wide Web to delegates at the Hypertext 1991 conference in San Antonio, Texas [CERN-IT-9112021-01] That drink on the table might be a margarita.
Still, the hypertext community wasn’t impressed. “He said you needed an Internet connection,” remembers Cathy Marshall, “and I thought, ‘Well, that’s expensive.’”
According to Cathy Marshall, a hypertext researcher who spent the majority of her professional career at Xerox PARC working on Note Cards and attended the conference, the Web’s first demonstration to the American public was a disappointment.
Compared with the other systems on display, the Web’s version of hypertext was years behind. Links on the World Wide Web went in only one direction, to a single destination, and they were contextual—tethered to their point of origin—rather than generic, like Wendy’s Microcosm links.
Representation of an anchor link in HTML
Instead of employing a linkbase that could update documents automatically when links were moved or deleted, the Web embedded links in documents themselves. “That was all considered counter to what we were doing at the time,” Cathy adds. “It was kind of like, well: we know better than to do that.”
Tim’s system didn’t hold up to the functionality standards that the crowd of researchers and hypertext experts at the time expected. Had they only realised that it’s one big advantage, that “very expensive” internet connection, would soon revolutionise the world. After two years there were already 50 websites in place and by 1994 the Web counted 2 million users, with 150,000 new users joining a month (Web History Primer, n.d.).
It certainly didn’t help that the techno-social activities of Hypertext ’91 featured a tequila fountain in the courtyard outside the hotel. The very moment the World Wide Web was making its American debut, everybody was outside drinking margaritas.
Ted Nelson, who already wasn’t happy with some of the developments in pre-web hypertext systems and had dropped out of the FRESS project at Brown as soon as it didn’t realise his full vision of XANADU, indeed wasn’t very happy about the Webs’ success either, as he postulated on his personal Website in pure ASCII text (Wright, 2007: 226).
Nelson, who runs his own YouTube channel, over the years and still repeatedly recites this critique as often as he can, as seen for instance at his self-proclaimed “Angriest and Best Lecture” in 2013.
He is very upset about the ‘bookish’ hierarchical structures that have been dragged along into this new networked medium. It is quite interesting for me, as a Typesetter, to be seen as a representative of that malady.
Markup, XML and the Semantic Web(3.0), which he calls out in ‘I DON’T BUY IN’, are Web technologies that are meant to improve machine readability. For Ted, this direction disregards the qualities of the system he wished for, which would be author-, and with that human-centred.
As Ted points out, the Web turned out to be, to some extent, top-down with “webmasters” being the sole editors of a static website. The previously high-held mantra of user=editor wasn’t fulfilled and with that, his vision of some kind of “re-use of content” e.g. transclusion wasn’t even closely resembled in the Web.
As Alex Wright points out in ‘Glut’, the functionality of links and the normative presence of Web Institutions, like the W3 Consortium are additional issues.
Nelson’s angry dismissal undoubtedly springs in part from personal disappointment at the Web’s ascendance over his own vision for Xanadu, which now seems relegated to the status of a permanent historical footnote. Nonetheless, he correctly identifies many critical limitations of the Web: the evanescence of Web links, the co-opting of hypertext by corporate interests, and the emergence of a new “priesthood” of programmers and gatekeepers behind the scenes who still exert control over the technological levers powering the commercial Web.
In his video series ‘Computers for Cynics’, he sounds much milder and makes clear, he still likes Tim Berners-Lee and credits him for the invention of the URL as his highest achievement, which “Harmonised and standardised network addressing, rational addressing across the diverse structure of Unix, Windows and Macintosh”. Nevertheless, he makes sure to credit all the original inventions that made the web, and with that Tims’ success, possible (TheTedNelson, 2012).
It must have been upsetting to him and others who had worked on, and dreamed about, hypertext systems at the time to see all their work being accredited to one man.
It is important to note that the Web isn’t one big invention, it built up on previous systems and implemented them. With that, it might be a beautiful metaphor for the structure of hypertext itself.
The Web’s popularity has proved a mixed blessing for the original hypertext visionaries. While its success has vindicated their vision, it has also effectively limited the research horizons for many otherwise promising paths of inquiry.
Sir Tim Berners-Lee being knighted by Queen Elisabeth II
Now that some dust has settled on the once visionary ideas of early hypertext systems and the Web has developed in ways then unforeseen in the past 32 years, it might be of value to do a little check-in on some key points and collate if they have found their way into our global network of today. Are there challenges opening up or have we found new approaches already? In the following chapter, I tried to consider and carve out emphases that I’ve noticed researching the pre-web systems and take voices of the hypertext community into consideration.
Interactivity & Collaboration
Thinking about FRESS and Intermedia, which were mostly thought out as collaborative tools where users weren’t just readers but writers and editors who could set their own links. Even in Xanadu, selected editors would compile new knowledge together. This functionality, although conceptualised in the early CERN days, didn’t make the cut into today’s Web.
The first ever web browser was also an editor, making the web an interactive medium, the problem was that it only ran on the NeXTStep operating system. With recent phenomena like blogs and wikis, the web is beginning to develop the kind of collaborative nature that its inventor envisaged from the start.
A screenshot taken from a NeXT computer running Tim Berners-Lee’s original WorldWideWeb browser. In the menu, the edit button is clearly visible. Links are marked through underlining.
Through social media and collaborative endeavours like Wikipedia, today’s Web(2.0) seems more interactive than ever before. Still, it’s important to note, that those platforms are always built on top of the Webs’ internal structure, which doesn’t allow editing or annotations on a structural level. They are interactive despite it, not because of it. HTML can be very limiting and people are trying to work around those limits.
Much of the Web’s interactivity seems to consist of discussions or commentary, emotional reactions e.g. ‘likes’ and personal messaging or content creation. In my eyes, it seems much more fragmented and ego-representative data compared to the idealised goal of collaboratively working together on something bigger, like building knowledge. One could compare this effect to the oral age translating into the digital space, a network of fragmented social information spanning between our devices.
Still, just in recent years, the rise of collaborative real-time online tools has started to take off more and more. A few examples are Etherpad for collaborative writing, Miro for mind mapping or Figma for designing and the Google Docs editors, in which I’m writing this thesis right now. They are examples of how the Web’s interactivity can be used in commercial and educational contexts.
Generating, editing and working together online has never been easier and more intuitive and Wikis are a great instance of voluntary many-to-many collaboration. They come in my opinion, closest to a community trying to edit knowledge networks together, like at Brown and at least represent the idea of colliding what we already know into Hypertext, as Ted Nelson dreamed of. Still, somehow they don’t quite hold up to the grand vision of global scholastic communities tightly conjoining on their fields or the universal approach of the Xanadu idea with everyone working together in one universal tool with proper citing and royalty systems established.
“It’s also frustrating that using hypertext has become more passive,” Andy says, “and that’s because of commercialization. When you’re on a commercial web page, there’s a rigid separation between creating and consuming
In early March this year, I made a shocking discovery. Many of the collections I had made within my Flickr account suddenly were almost empty, what a loss! A visit to the forum soothed me, that I wasn’t alone but soon brought bad news: the contents of The Internet Archive Book Images account had been deleted from the platform without warning.
This is devastating, had to be my favourite thing on the internet, no hyperbole.Please tell me the metadata was backed up before the account was deleted? In theory the images are still somewhere in the internet archive (not in a browsable form).. but all the time people spent exploring the 5 million plus images and favouriting them + adding them to galleries, just gone?Even just the view counts for each image would allow the most popular images to be found again..
What this upset user pointed out, was very true. The metadata generated within the huge dataset maybe was just as valuable as the continents themselves and with it an interface that supported the categorising.
With great masses of data and information, it gets harder and harder to navigate and work out the knowledge it might entail. Tagging and sorting are two exemplary bottom-up indexing strategies that have thrived in a flat hierarchy Web.
Now I’m sure Ted Nelson would like to differ, as he thinks that HTML is a terribly hierarchical markup-template-hamburger. And he might be right, but in the grand scheme of things and at a structural level, the Web is a network of documents equal to each other and connected by links, just as in “As we may think”.
Bush, by contrast, envisioned a flat system with no classification scheme. Indeed, the Web’s openness and lack of hierarchy—for better and worse—has strong conceptual roots in Bush’s bottom-up document structure.
There is no ingrained central Index or table of content to the Web like we know it from libraries, printed encyclopaedias or the Mundaneum. So besides hyperlinks, how do we actually navigate the Web if not top-down? By algorithm-driven search engines like Google, which have basically replaced typing URLs.
A great advantage of digital text is being able to perform a full-text search, but the computing power needed just wasn’t there with early hypertext systems. I found that Intermedia must have already implemented a similar algorithm but seems to be the only system researched that advertised search as a feature. It seems like the trailblazers didn’t quite grasp the full power search could unleash.
Google’s PageRank revolutionised search because they understood that frequency isn’t the only aspect of a good result, quality is too!
Nonetheless, navigation was a big issue that was discussed by researchers at the time. There are two main functionalities I could observe.
One was graphical maps of the network, similar to tree diagrams or mind maps. They were a very popular approach and could be found within FRESS, Intermedia and Hypercard. From what I’ve seen they were also used for following hypermedia systems. I’m actually quite surprised they haven’t really caught on and found their way into the Web. It might have been due to the immense growth that would have hit illustrative limitations quite quickly, but it’s not hard to imagine them with some kind of zoom capabilities or at least as a navigational element on singular websites instead of hierarchical header menus.
The second is observed in the semantics of FRESS, through the separation of structure and formatting, contrary to HTML. This gave opportunity for different depictions of the contained contents, combined with the aforementioned keyword tags and filter options.
The user can view just the top n levels of the structure — a map whose level of detail is defined by the user. This facilitates rapid movement between sections and makes editing and global navigation easier.
FRESS provided a variety of coordinated views and conditional structure and view-specification mechanisms. The user had final control over how and how much of the document was being displayed — unlike with embedded markup like HTML.
From how I understand it, this kind of functionality, although desirable, would be hard to implement on the web due to its manyfold content types and structures. Still, some individual websites are making an effort of offering adapted options for navigational structures to their content. Most welcome from my perspective.
Diagram showing ‘simple’ monodirectional links, just like the Web’s Hyperlinks today
The Web’s lack of bidirectional links, as mentioned before, was alienating to most Hypertext researchers at the time. In a bi-directionally linked network, both parties know about being linked and both documents can refer to each other, which can enrich one and the other. To my knowledge FRESS, Intermedia and Microcosm were using links that went in both directions. At Intermedia, they were stored in an additional database. They also used ‘fat links’ which are multidirectional, so one anchor could hold links to multiple targets.
the technology to handle a worldwide database of bidirectional links was untenable at the time. But it made the web incredibly fragile – if someone renames a document, all the links pointing to that document break and produce the dreaded ‘404 error’ when followed
And while linkbases and constructive hypertext were easily maintained in relatively contained research and classroom environments, or on small networks of computers all running the same operating system, they would have quickly become unmanageable on a global scale.
Experts suggest it would’ve been impossible for the Web to implement and upkeep an external database during its exponential growth. Still, Tim Berners-Lee must have considered the option, as one can trace in his notes. In the end ‘back links’ turned out to be an important factor for Google’s PageRank algorithm to estimate the importance of a page.
To build a system that wouldn’t be able to prevent link rot seemed irresponsible at last to the early hypertext crowd as well. Link rot describes links that lead to nowhere, causing an error as the reference document has been lost, deleted or changed location. On the Web, it leads to ‘Error 404’. Most of the previous systems either prevented that by automatically updating links when documents were moved or deactivated the connection automatically once the target document was deleted. The Web tries to counteract this problem through permalinks or crawlers that search for dead links, quite ineffectively. A recent Harvard study took the New York Times as an example and found that a quarter of its deep links have already been rotten. (Clark, 2021) A big problem for traceability on the Web.
This graphic represents the nature of hypermedia links as both the static, discrete node-link relationships characteristics of traditional hypertext and as the dynamic, continuous forms seen in contemporary systems.
Another factor to consider when evaluating links is granularity or as Van Dam puts it ‘creaminess’. It defines how detailed links work, with the finest granularity being one single letter. Intermedia provided a very fine grain, so when following a link it would lead you to the desired paragraph, word or graphic. You can see it in action here, note how the desired target note is highlighted through a blinking dotted frame. FRESS had similar functionality.
On the Web, high granularity is mainly possible within the same document. As soon as one links to a node outside, it is most likely a generic URL to a whole document. There are exceptions, like target websites that provide a higher granularity, for example, YouTube which allows generating links to a specific video start time.
Something that hasn’t been noted above is the collaborative nature of link-making in all of Brown’s systems. With users as editors, they naturally were able to make their own links that would become part of the content and were visible to other users, contrary to the Web, where links are embedded within the document by one author. Intermedia even went a step further and implemented an individual web of links, separate from the document, that was stored in an external database. The closest the Web gets to that is probably bookmarks, but they aren’t really comparable considering the depth of functionality. Del.icio.us used to be a popular platform for social bookmarking and stands as an example of how valued the social aspect of linking can be.
Bush’s idea of linked trails through heaps of information is also found in some of the pre-Web systems. In Intermedia and Microcosm Mimics, specified paths could be defined and shared, this was mostly advertised for educational purposes and re-introduces linearity into the networked system that can help beginners navigate or set up a certain narrative. Hypercard inherently adopted some kind of linearity through the stack metaphor and with that was mostly consisting of thematic paths, which arrows as a main interface element. Maybe today’s browser history somehow represents a trail, but it doesn’t really paint a clear or defined narrative, nor is it meant for sharing.
As Ted Nelson seems obsessed with visual links it is worth a mention here, I think opposed to just visually implying there is an underlying connection, his definition of ‘visual’ implies showing the connected source link right next to where it was implemented, so it’s always put in context. This idea is very close to the two-display concept introduced by Bush but doesn’t seem to have caught on.
Last but not least Alex Wright brings up an interesting idea that resonates a bit with how FRESS was set up and Otlet’s Universal Decimal Classification. In a Google Tech Talk, he explains that links could also carry a meaning, he calls it gradation of links, which could imply the relationship between the two nodes, if they agree or disagree etcetera. We already know of a similar adoption in FRESS, where links could be tagged with keywords. Maybe something similar is thinkable using classes or IDs in HTML.
People can easily fall into the belief that the web is ‘done’, but there are tons of things, like links that don’t break, that existed in Brown’s systems in the past and hopefully will find their way into the web of the future
Citing on the Web or generally in word processing environments today is still extremely tedious and faulty. Even with helpful tools, like Zotero, that I’m using for this thesis or citation checkers, mistakes can sneak in, links can break and with each layer of citation, it gets more unclear who said what or it gets distorted through paraphrasing. The clipboard with its copy-paste mechanism might have made the process easier, but technically how we cite hasn’t changed for centuries. Links just sped up the process.
Ted Nelson’s proposal for transclusion in Xanadu to me seems to me like a fresh breath of air. The idea to include a citation by pulling and linking it from its original source instead of copying and ‘swallowing’ it, seems only logical. It keeps the content original, reference chains intact and provides direct access, plus an update to the latest version if requested. Intermedia did implement a similar feature, the pull request as shown here. In the example, a graphic is ‘pulled’ into an existing text document and then displayed within. When edited it is updateable. Of course in Intermedia this was easier to accomplish as it only entails a local network.
I understand that to be able to rely on the technology, a Xanadu-like closed and universal database would have to be implemented somehow. Otherwise, we would deal with similar issues, like broken transclusions. Some people see the blockchain as a solution to that - I’m not too sure about that.
The Web actually provides a similar technology through ‘embedding’, videos and iframes can be included in a website and live data can be pulled from external databases, like the universal time.
Still, to my knowledge, there isn’t a system in place for low-granularity text embedding, which would be gratifying. Iframes can be notoriously unstable which is another indicator to work on a more stable system of trust and source reliability.
Using a typical Web link, you change context and engage with new text as you might by going to a library and following a citation from book to book, pursuing a parallel rather than an “inclusive” relationship.
Archiving the Ephemeral Web
Through extensive content shifts and link rot as explained above we have to admit that today’s Web is ephemeral. Although previous systems have employed technologies to prevent those and solved some issues of version control, they all have a common flaw, when examined for their longevity and resilience in order to accommodate the world’s knowledge. They are embedded within their systems, which couldn’t withstand the pace of technological progress, and weren’t accessible within just a few years. Databases have been translated from diskettes to LaserDiscs to CDs to the Cloud. Although we made a great leap forward by being able to store data as bits, we still haven’t figured out a stable enough system of formats to trust for such a big task of preservation. Maybe digital capability hasn’t surpassed paper qualities just yet, as it is stable and directly accessible.
Ironically microfilm still is the most durable option we have today for ensuring longevity, as it’s less susceptible to environmental factors. So Bush’s Memex, although seeming a bit antiquated, still offers the most reliable alternative to our paper libraries today, taking up only a fraction of the space. No wonder it’s the chosen technology for state archives, hoarding rolls and rolls of film in some underground rock tunnel.
Nevertheless, the Web has stuck around with us for 32 years now and we have to take care not too much knowledge is lost in the meantime. The Internet Archive’s Wayback Machine is doing a great job by archiving as much as possible whilst trying to ensure some kind of directed quality control. Right now it has saved 734 billion web pages (“Internet Archive,” 2022) next to its further functions as a digital library, still, it’s like rowing upstream and only so much can be archived. That all these efforts only rely on a voluntary non-profit is insane to me.
It’s vital to recognize that not everything is culturally important and in many cases, especially online ephemerality is desired, like in Snapchat for example.
Accessibility & Copyright
Now let’s discuss a core question. The question of value concerning electronic documents that can now be reproduced indefinitely and cheaply published to a global audience with ease. How can we ensure rights and royalties are retained for authors and creators and at the same time provide accessibility and re-use to as many people as possible when translated into an online hypertext system?
I know this is a problem that probably won’t be solved just by implementing new technology in some systems. It might require global legislative action, and this thesis can only touch on the issue, but still, I feel it needs to be addressed within this conversation of how we want the Web and future hypertext systems to evolve.
A “Biblioburro” donkey library provides book access to remote places.
In the Web’s early days, it was all about openly sharing scientific knowledge. To quote Tim Berners-Lee again:
The project started with the philosophy that much academic information should be freely available to anyone.
There was a spirit of community building that didn’t care much about licences and rights. What would later be called ‘online piracy’ thrived, because it was so easy on the Internet.
Today information on the Web is not really free. A big chunk is blocked by paywalls or enwrought with advertisements and somehow financed by data resellers.
The Internet simultaneously holds both the utopian promise of free access to all the world’s knowledge and the dystopian potential for the privatisation of all knowledge for the profit of small number of monopolistic corporations.
In contrast to those commercially motivated monetized systems stand online hacktivists like Aaron Swartz, Institutions like the Internet Archive with its Open Library and shadow libraries, who fight against the blocking of access. They are true believers of the world library and are convinced it should be implemented now, either through piracy on platforms like Library Genesis or Sci-Hub or through a library-like lending system, implemented at Internet Archive, which currently is the cause of a critical lawsuit with big publishers, that will decide if it can make use of the fair use policy.
(LTR) Ted Nelson with Aaron Schwartz and Douglas Engelbart in 2001 at the International Semantic Web Working Symposium held at Stanford University.
When it comes to academic publishing it gets even more complicated, because it involves prestigious journals and peer reviews. Basically, government-funded scientists write papers, that are reviewed by other government-funded scientists, that then are published by journals that earn a lot of money, paid by libraries funded by the government for people to access the papers. Sounds pretty fucked to me.
Open Access tries to break this vicious circle by convincing scientists to openly publish their papers, to make them accessible and free to reuse. Something that is only possible because of the Webs structure, but it seems like so far the scientific community is having a hard time letting go of old established ways and adopting new relevance criteria.
In other fields, the creative commons licences are a possibility for creators to make their work open to sharing and re-use.
Once copyright expires, usually 50-100 years after the author’s death, in the US the work will be public domain. Project Gutenberg uses that to publish those for free as ebooks.
It gets complicated when the rights are unclear, as proven by the lawsuit around google books, when they tried to implement the world brain all by themselves. What they got was the self-proclaimed world's most comprehensive index catalogue.
In August 2010, Google put out a blog post announcing that there were 129,864,880 books in the world. The company said they were going to scan them all.
They just started carting truckloads of books from big university libraries to a scanning centre for them to be digitised through optical character recognition.
The idea was that in the future, once all books were digitized, you’d be able to map the citations among them, see which books got cited the most, and use that data to give better search results to library patrons.
Google planned to make the books searchable and display snippets to users, just like the system is implemented now. Still to provide that service all books have to be scanned completely. A developer commented, they could be opened up for the world to read within minutes.
Somewhere at Google there is a database containing 25 million books and nobody is allowed to read them.
The Atlantics trial article is worth a read, as it unfolds the complexities of the copyright question in all its ugliness. In the end, the problem of how to deal with out-of-print publications and ones with unclear rights status wasn’t solved but postponed.
The examples set out above are supposed to draw a picture of either extreme, commercial usage with walls around knowledge, or full access through shadow libraries that ignore the laws and with that the creators and authors, whose work they actually value.
There has to be a compromise. Authors shouldn’t have to give away their work for free, because there is no hope of being compensated fairly on any side. Maybe technology can offer solutions, but there will have to be some legislative decisions.
To draw back to hypertext systems, Xanadu was the only proposed system to address this issue, copyright at an infrastructural level. Ted Nelson was convinced that within his closed environment, micropayments per read and usage, directly to the creator, could offer the solution to this crux.
I must admit he had me intrigued. But as easy things can seem in concept as important they can be in implementation. In his most recent ‘demo’ of Xanadocs he shows how restricted content would be displayed: ‘encrypted’ as Webdingstofu. To me as a designer it just seems like a very clumsy solution, that obstructs the flow of the document too much. But at least he is trying out new solutions, we need more of that momentum.
Stretchtext, one of Ted’s early ideas could also be considered an asset for accessibility in a different realm. He suggested a kind of detailed adjuster for the complexity of text as part of the interface. It’s imaginable in levels for example as kindergarten, plain language, high school, college, and PhD. While there are already examples where another option of text complexity is offered, editing still often is too much of a time/cost factor. In the future, it is quite imaginable to see these options automatically generated through text-based artificial intelligence, like GPT-3.
Although dictionaries for defining specific terms had been thought of in Intermedia, another similar valuable aspect, that had been completely overlooked in previous systems, found its way into the web: automated translation. This allowed a much greater audience to participate. If we want to expand this capability we should ensure all the world will be able to participate in the open web, not just on Facebook satellite service. In some areas, a DVD on a horse is still a faster way to transmit data than the Net, even in Germany.
It’s hard to measure exactly, but according to Internet Live Stats, at the time of writing this thesis, there are 1.9 billion websites online (less than 200 million active) and 5,4 billion Internet users in the world. WorldWideWebSize puts it at a whopping 3,4 billion indexed pages, either way - it’s huge (Internet Live Stats - Internet Usage & Social Media Statistics, n.d.)(WorldWideWebSize.Com | The Size of the World Wide Web (The Internet), n.d.).
Without a doubt, the advent of the Web has been “central to the development of the Information Age” and catapulted itself to be the “world’s dominant software platform” (“World Wide Web” 2022) in a very short time span. It might be the most quickly adopted way of communication and sharing information in our species history.
Twenty years after Johannes Gutenberg invented his printing press, a bare handful of people in Germany and France had ever seen a printed book. Less than 20 years after its invention, the World Wide Web has touched billions.
Why exactly it took off the way it did goes beyond the scope of this thesis, but some of its advantages are for sure its compatibility with many devices, easy access to content as well as being fast, always up to date and easy to share. Certainly CERN’s decision to give it away through open access made a big impact and influenced much of the web 1.0 spirit of freely sharing data.
the Internet is one further step in the evolution of publishing, and the development of a universal online library of all the worlds’ knowledge is its inevitable and desirable outcome.
In the end, I think it’s great how the Web steamrolled its way into very established publishing and licensing systems and opened up some heads to the possibility of what accessibility could look like. A true grassroots equaliser that gave freedom of information to people that will be hard to take away again. It already reached so many that didn’t have a grasp before and with that greatly surpassed its hypertext predecessors, maybe because of its simplified many things at its beginning. An adapted royalties system must and will be found sometime.
The Xanadu hackers may never have produced a working implementation of their design, but they possessed a profound foreknowledge of the information crisis soon to be produced by digital technology. They were dead-accurate when they sketched a future of many-to-many communication, universal digital publishing, links between documents, and the capacity for infinite storage. When they started, they had been ahead of their time.
Andy Van Dam puts it quite well when asked about the Web’s ability as a host system to the world’s knowledge. To an extent, it is providing that experience, but most of the information is raw, of unknown origin and with that questionable reliability. He sees it as the human’s job now to make sense of it and actually build knowledge from surfing this sea of data and information. If you read Wikipedia you really have to go back to the primary sources. (Martin Wasserman, 2009)
The Web may not be the host to all of the world’s knowledge yet, but within its structure one of the closest resembling systems to the world encyclopaedia emerged: the wikis. And with that one wiki to rule them all, Wikipedia, the largest and most known encyclopaedia in the world. With 2 billion visits per month, it is the 7th most visited website, after search engines and social media. Even ranked before Pornhub, and probably is the only non-profit in the group.(Wikimedia Statistics - All Wikipedias, n.d.) (Meistbesuchte Websites - Top-Websites Ranking für September 2022, n.d.)
Wikis at their essence are a free and open hypertext system, they implemented the collaborative approach in building knowledge together, as a community at heart, accessible to everyone. They completely broke with the elite-based rule of thought by their ancestors, like the Encyclopaedia Britannica and can be seen as a stripped-down version of systems like FRESS or Intermedia. It makes it the best example we have today for a hypertext-based knowledge network striving to swallow all knowledge out there.
There is no central Wikipedia index, it is mostly navigated through search and linking, sometimes link lists, which makes it a low hierarchy system, with taggable pages. It even encourages that through its ‘random article’ button and a landing page filled with ever-changing wikilinks. Wikilinks are similar to hyperlinks, but each page features a ‘see also’ segment that fulfils a similar role as backlinks, which some wikis even implemented. It’s also possible to link to a non-existing page, to indicate it should be created.
The most complete realisation of the universal world encyclopaedia concept expounded by both Otlet and Wells is the Web-based encyclopaedia Wikipedia, which is universal in scope, far larger and complete than its predecessors, and freely licensed. However, although there are a myriad of rules and guidelines in place, it is operated entirely differently: by (usually anonymous) volunteers, and it exists as a registered charity, independent of any direct governmental or existing international association support and influence. In short, it is based on trust rather than expert authority, and can be considered a perfect demonstration of how the larger Internet as a whole differs from the predictions of Otlet and Wells.
Last Thoughts
Now, what do I make out of all this? Is the Web the hypertext system that entails our world brain? I don’t think so. Will it be? Time will tell. It definitely laid the groundwork, but 30 years aren’t long on the scale of human progression. We just got started with something exciting and carried our old conventions into that new realm, the next decades will show if the growing pains discussed above will be addressed and how. One thing I’m sure of though, the vision of colliding all of humanity’s knowledge into a universal system will further infect people’s minds. The Memex and Project Xanadu protruded between all these things I’ve read, they seem most influential because they represent an idea, a dream and haven’t met the compromise of reality. At the time the technology just wasn’t ready for their vision, but now it’s right there on the horizon.
To me the key technology to these universalist dreams is the Internet, I hope future generations will further relish this worldwide network. How we navigate it, how interfaces will change, all that is up to debate. Compared to the advent of the Gutenberg press, after which we established common norms, sizes and conventions, we’re in the middle of the said process of this ‘new’ medium.
The Knowledge Box by Ken Isaacs
Another thing that boggles my mind, is despite all efforts of shadow libraries and other entities like google, somehow the analogue book body of knowledge still hasn’t been appropriately swallowed and translated into the Web. Qualitative Wikipedia articles in the end just cite books in the good old way. Sure, uploaded PDFs make the ones online shareable, still they are somehow isolated, far away from an interconnected Xanadu network that will bring new knowledge to light through links. The reasons have been discussed before and I understand the complications, still we have to consider the implications of leaving this cultural heritage and treasure behind. I fear it will be much easier to just access digital information that the old knowledge might be neglected and we can’t let that happen.
For all its limitations, however, the Web’s colossal success serves as a ringing vindication of its forefathers’ vision. While it may be far from perfect, the Web has proved to be an enormously important democratizing technology. It is a profoundly humanist medium, open, accessible, and largely populated by nonprogrammers who have found ways to express themselves using a panoply of available technologies.
It’s interesting to me how the motivations that drove progress to Web technology, ideas of sharing knowledge and collective knowledge building, and scholarly ideology, don’t truly reflect the Web we have today. Maybe they were a bit delusional? To me, the present Web shows that most of what we do everyday isn’t academic at all.
What surprises me though is, that as soon as Web technology was there and growing exponentially it seemed to have swallowed a whole generation of hypertext scientists that believed in systems that could do so much more. Intermedia and Hypercard were so complex, well-engineered and functional, still somehow our desktop environments today don’t reflect that referentiality they pioneered. Why did those educational or personal knowledge bases just stop and leave us with plain word processors, the document metaphor and enclosed PDFs?
Now I know, all this is expected a little too much from the Web. I made sure to beat around on all its shortcomings in comparison to previous functionalities, but if we can learn one thing from Xanadu it’s that we shouldn’t expect everything from one single system. Ted tried to push all his hopes and dreams into it, how could it ever fulfil them?
The Web has already proven to be so much more than we expected from it, why not build a new, improved, separate internet-based system for scholastic purposes? One that can live up to the complex demands of academic work, that would encourage scholastic discourse without drifting apart like a comment section. One with multifunctional links and shareable trails. One that grants transcluded, traceable references and that can be archived properly. A Xanadu that doesn’t try to swallow everything all at once and ends up being a nightmarish Library of Babel, and a Wikipedia comprising all important books, where scholars and students produce new knowledge alike, supported through a smart royalties setup. One can dream at least, right?
Such a system will represent at last the true structure of information (rather than Procrustean mappings of it), with all its intrinsic complexity and controversy, and provide a universal archival standard worthy of our heritage of freedom and pluralism.
We are but knots within a universal network of information flux that receive, process and transmit information.

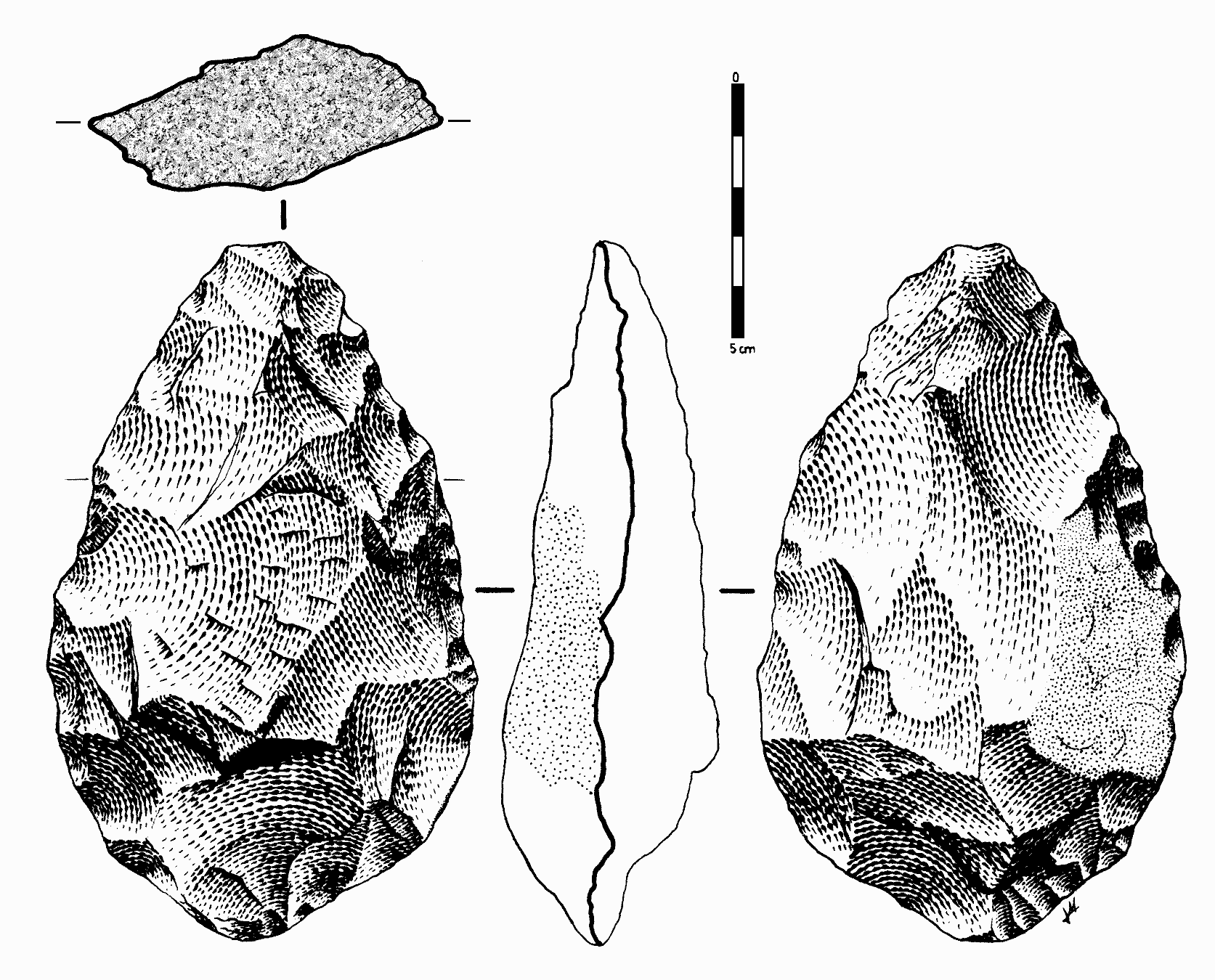











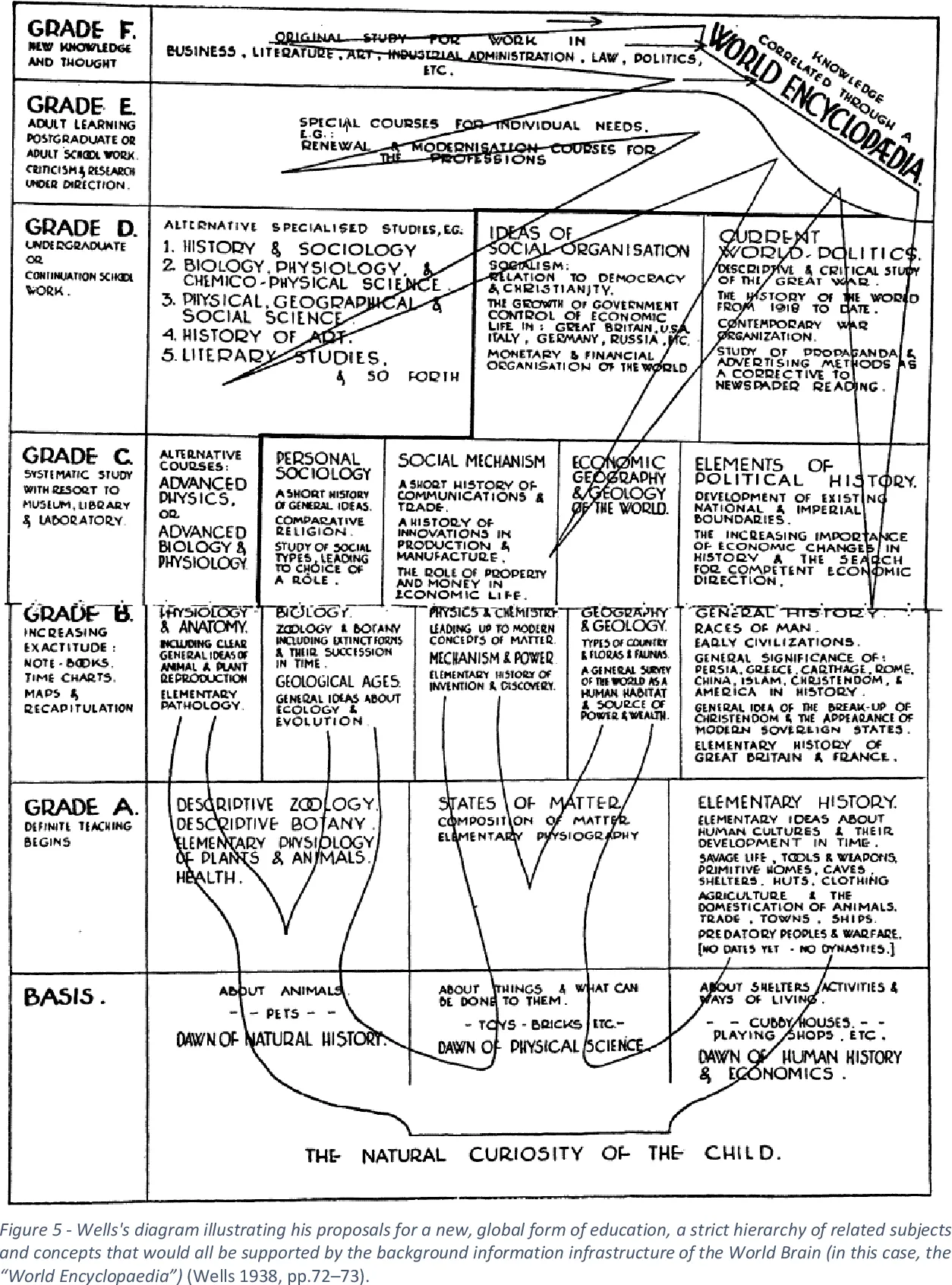




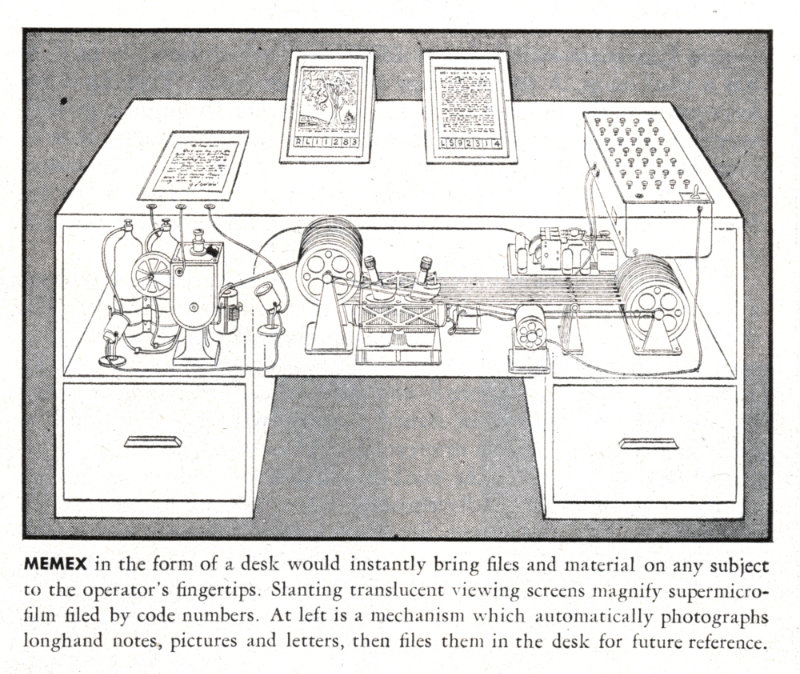

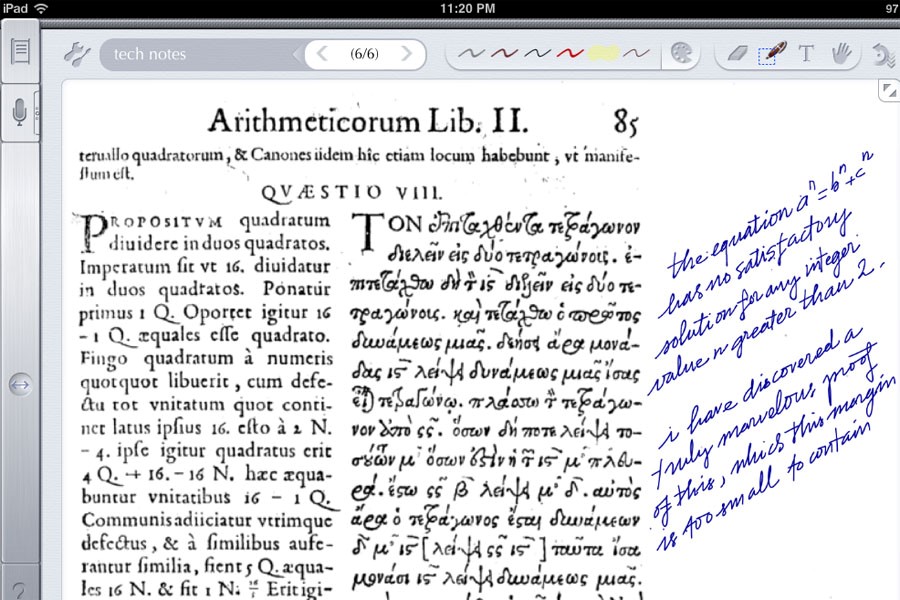



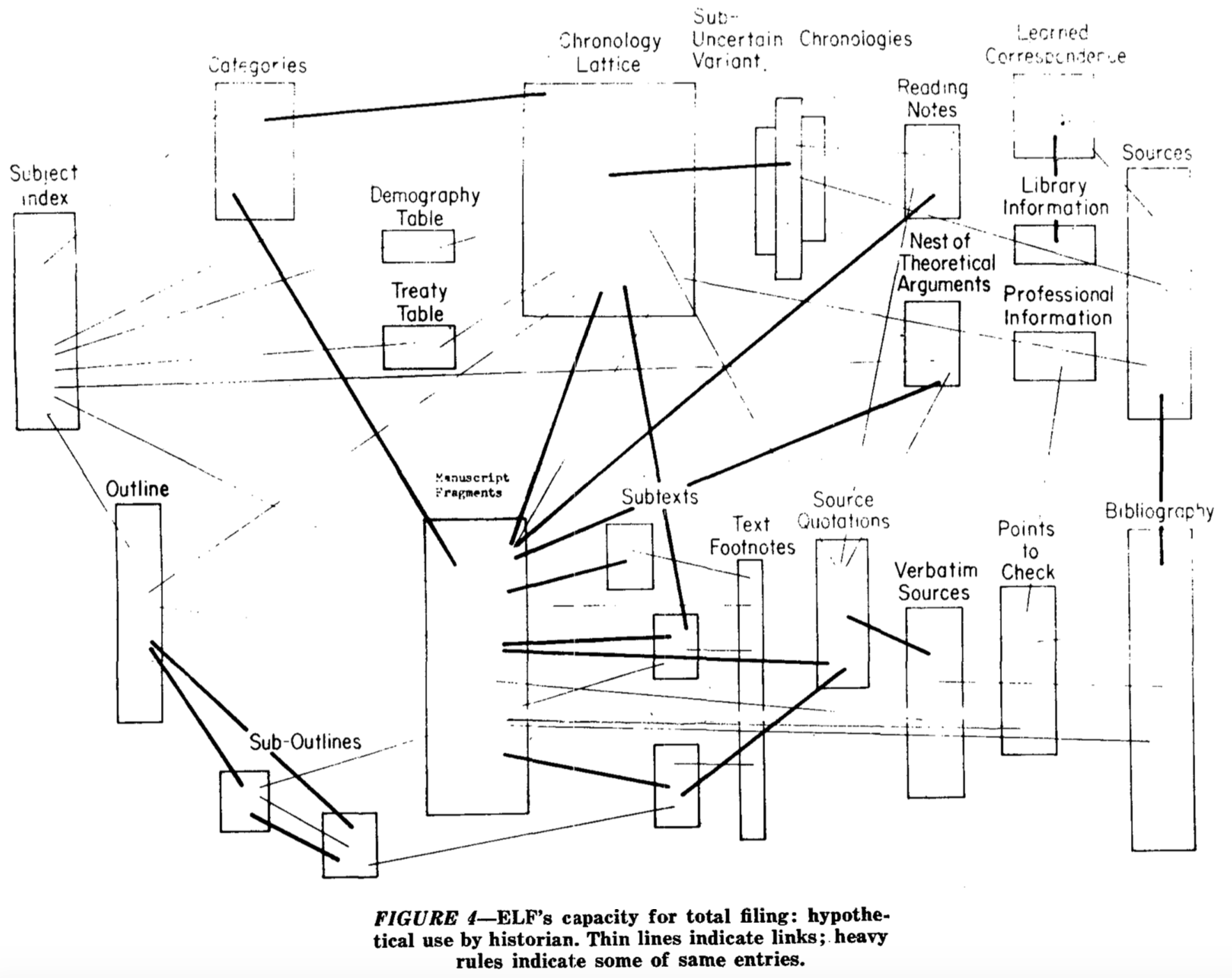


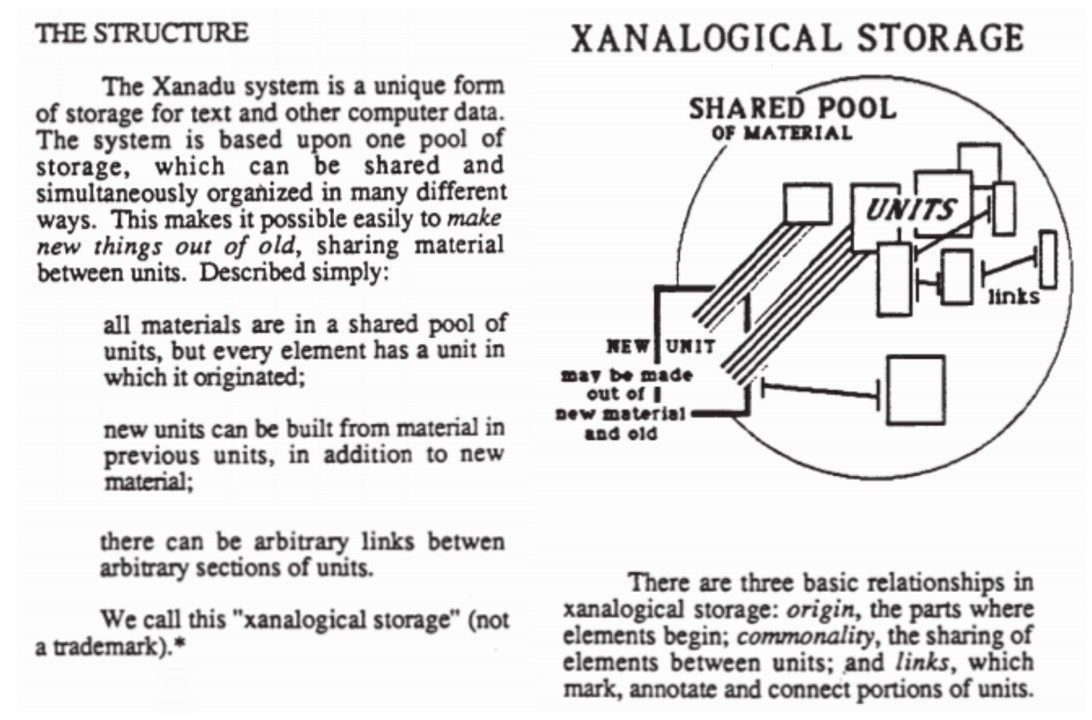


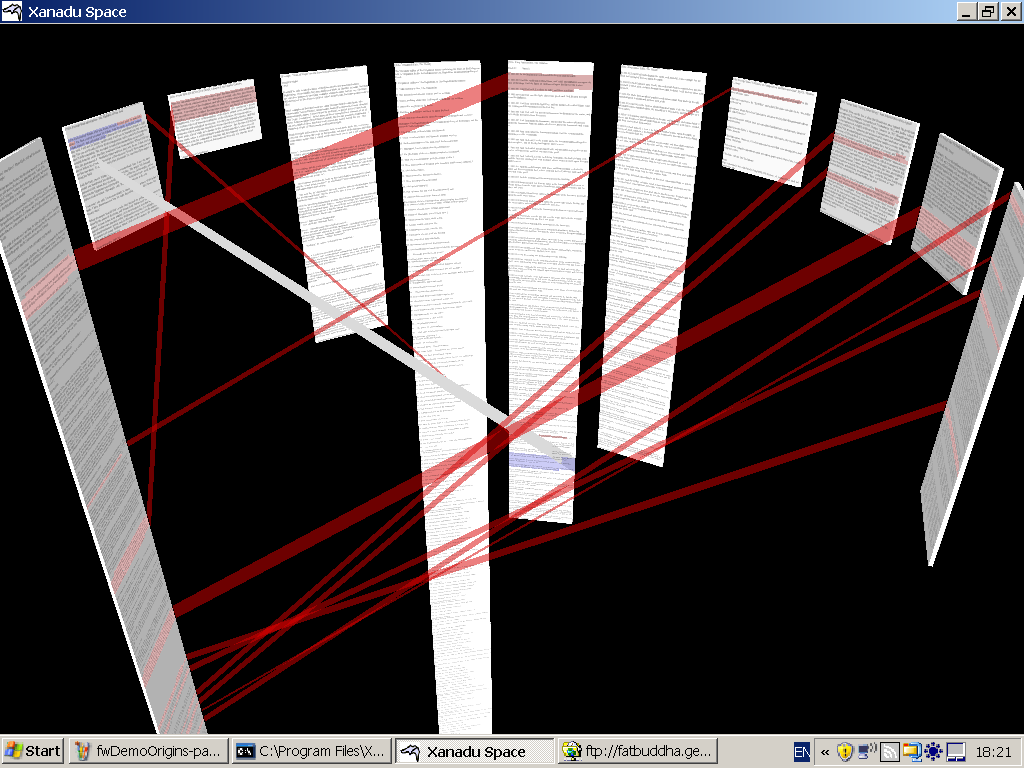




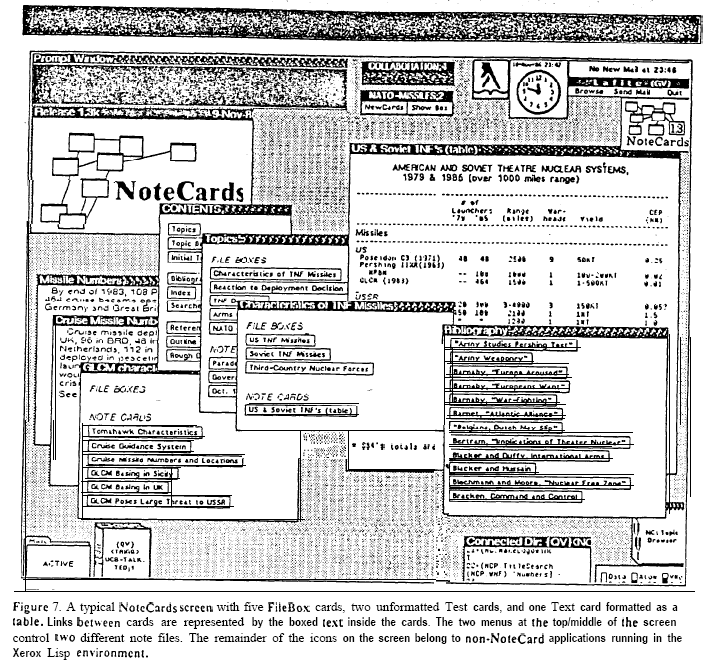



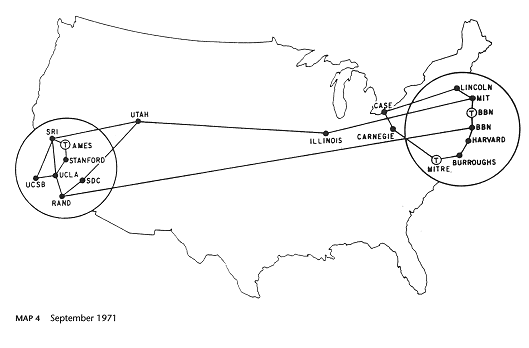
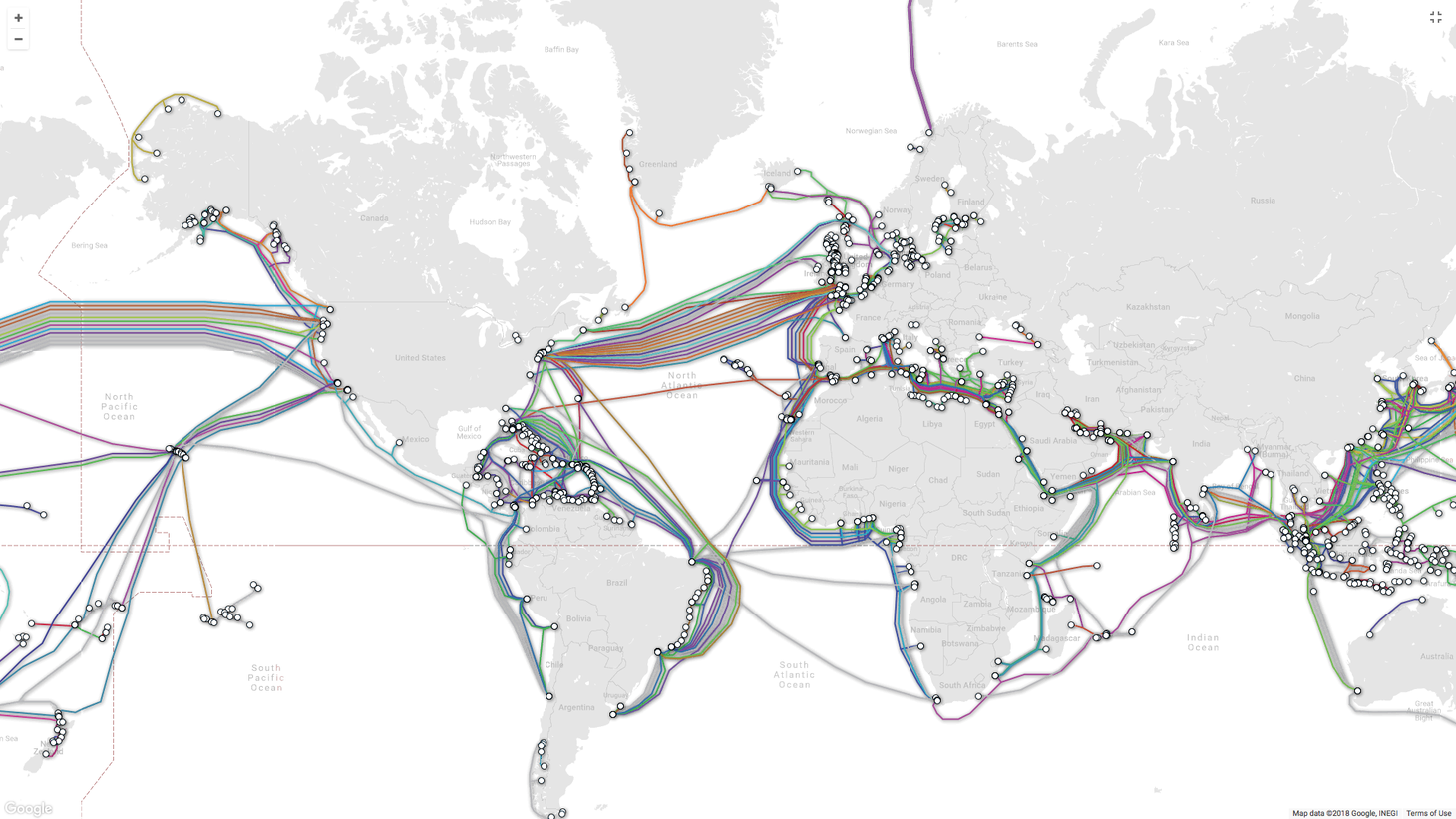



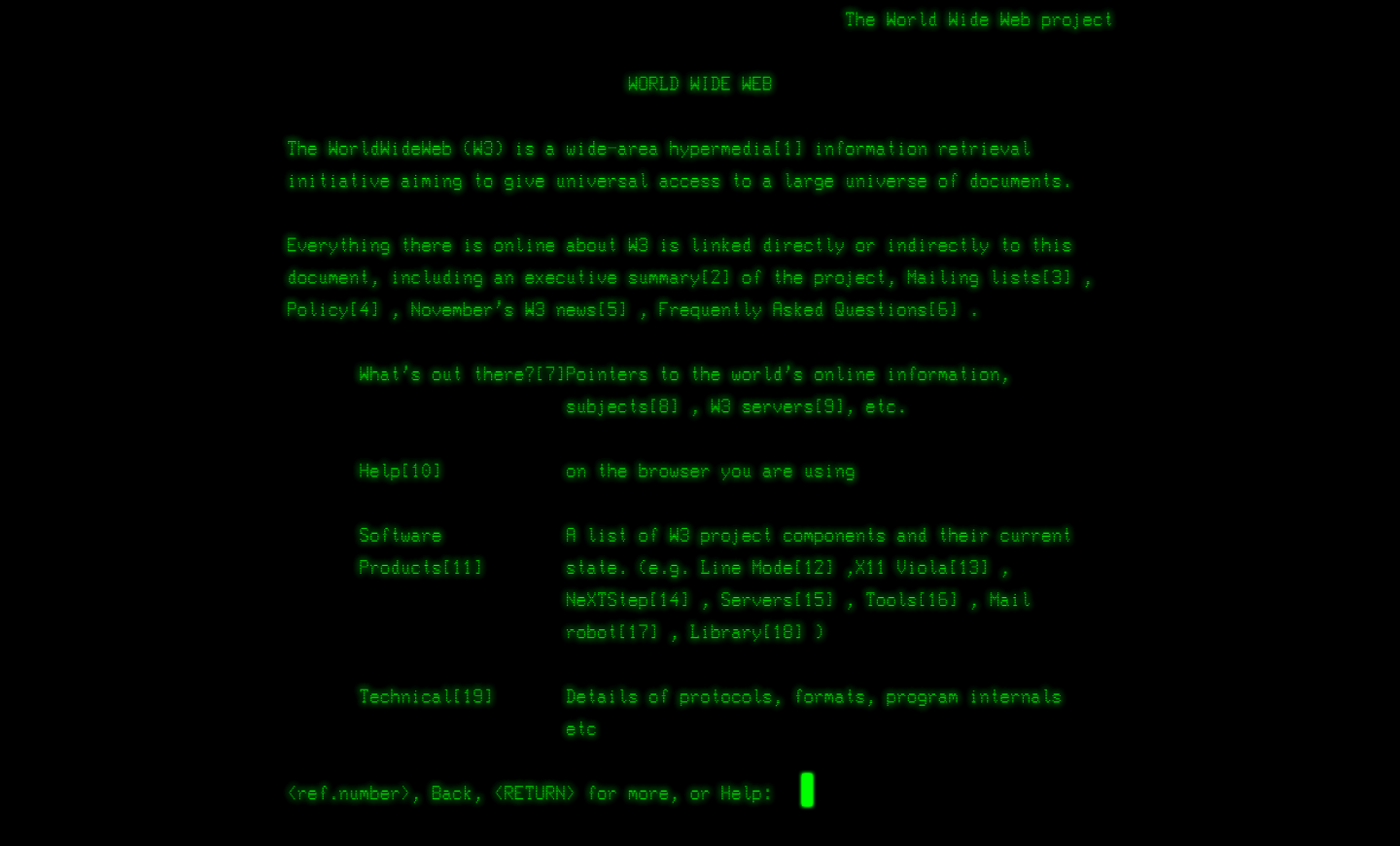
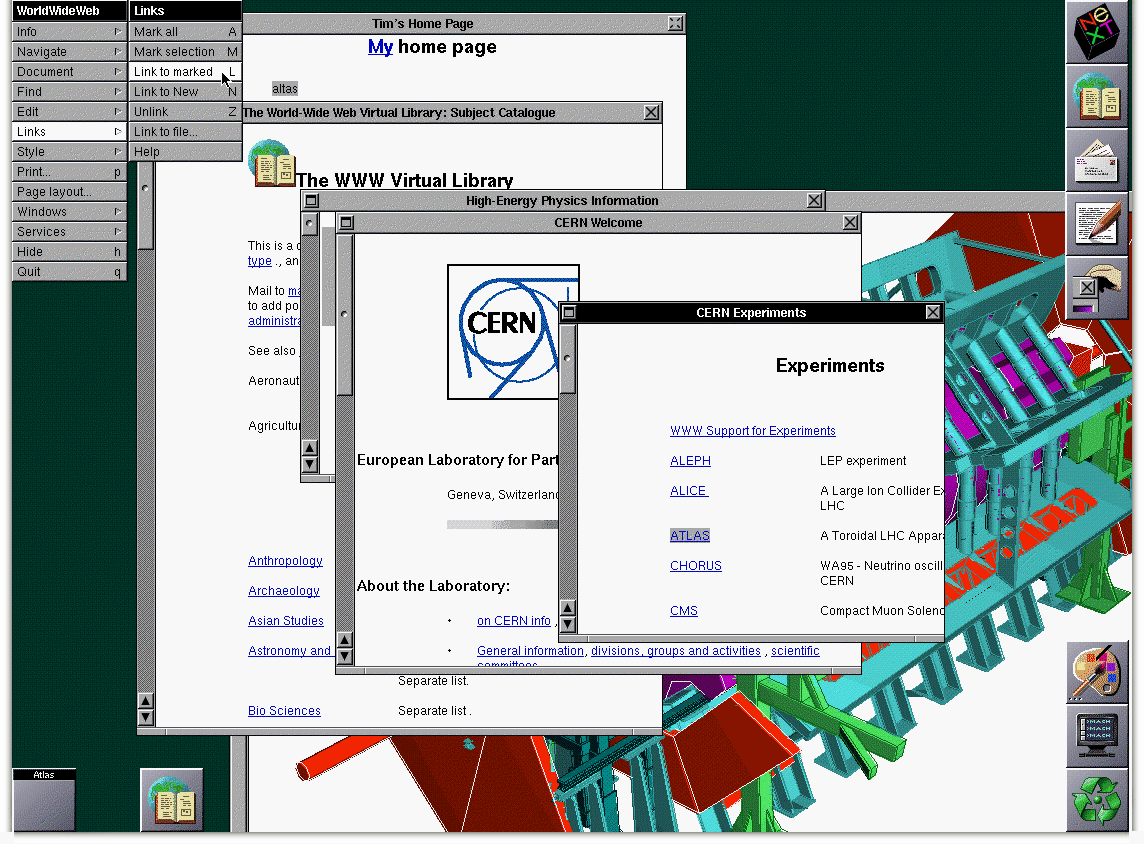




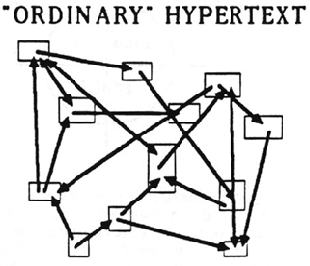

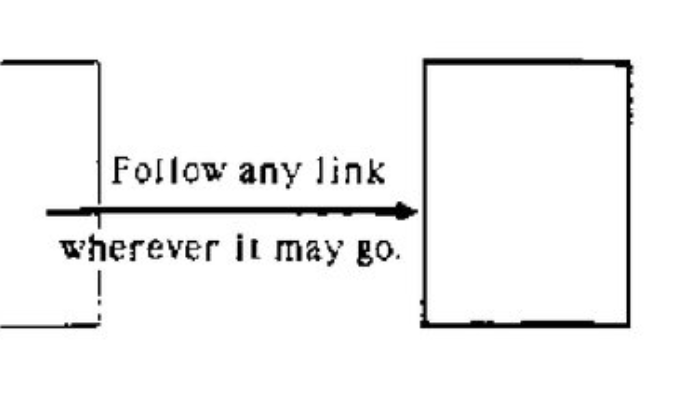


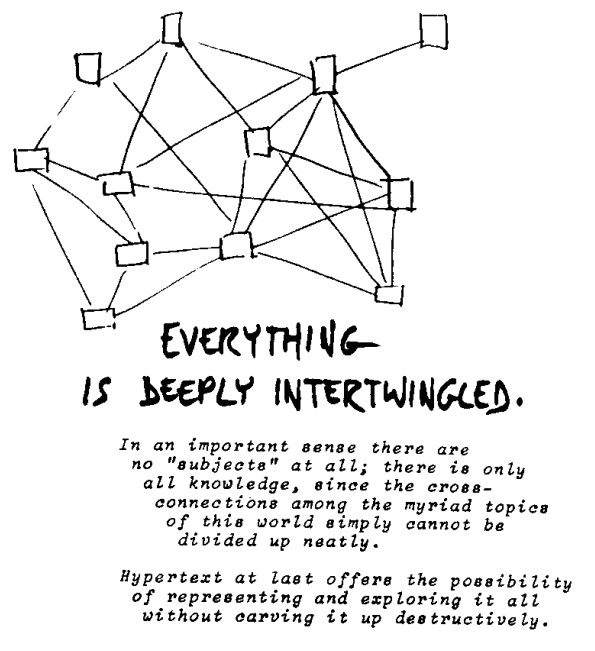
{kind=link}